Updated Apr 2 11:30:00 CDT 2015
In this assignment you will run a machine learning experiment using Weka, an open source framework for machine learning and data mining. You will generate a model that predicts the quality of wine based on its chemical attributes. You will train the model on the supplied training data and use the model to predict the correct output for unlabeled test data.
You'll turn in your homework as a single zip file, in Canvas. Specifically:
PS1.txt.
PS1.model.
PS1.arff.
PS1.txtPS1.modelPS1.arffWeka is available for Windows, Mac, and Linux from http://www.cs.waikato.ac.nz/ml/weka/. Click on the "Download" link on the left-hand side and download the Stable GUI version, which is currently 3.6. You may also wish to download a Weka manual from the "Documentation" page.
Note
Some points that may help with Weka installation on Mac OS X:
- The Weka download page lists a version that works with JVM 1.6 and one that comes bundled with JVM 1.7. If you have a JVM version higher than 1.7 already installed on your Mac, you should download the Weka version bundled with JVM 1.7.
- Installing Weka on a Mac simply requires copying the downloaded contents to a new folder under Applications. In other words, there is no .dmg file to run.
The dataset files are here:
This dataset is adapted from:
P. Cortez, A. Cerdeira, F. Almeida, T. Matos and J. Reis. Modeling wine preferences by data mining from physicochemical properties. In Decision Support Systems, Elsevier, 47(4):547-553. ISSN: 0167-9236.
This dataset contains data for 2700 white variants of the Portuguese "Vinho Verde" wine. For each variant, 11 chemical features were measured. Each of these is a numeric attribute. They are:
Each variant was tasted by three experts. Their ratings have been combined into a single quality label: "good" or "bad" Therefore this is a binary classification problem with numeric attributes.
The dataset has been randomly split into a training set (1890 variants) and a test set (810 variants). The training set contains both chemical features and quality labels. The test set contains only the chemical features.
View train.arff and test.arff in a text editor.
You should see something like this:
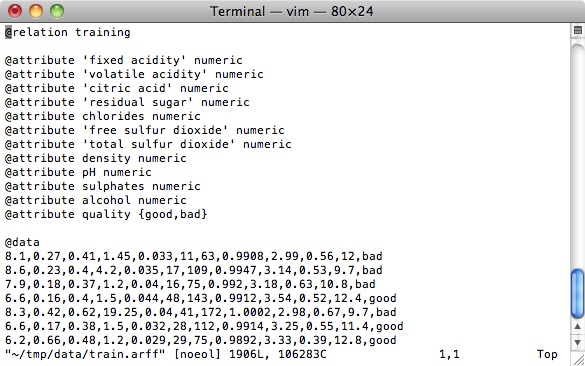
The files are in ARFF (Attribute-Relation File Format), a text format developed for Weka. At the top of each file you will see a list of attributes, followed by a data section with rows of comma separated values, one for each instance. The text and training files look similar, except that the last value for each training instance is a quality label and the last value for each test instance is a question mark, since these instances are unlabeled.
For this assignment you will not need to deal with the ARFF format directly, as Weka will handle reading and writing ARFF files for you. In future experiments you may have to convert between ARFF and another data format. (You can close the text editor.)
Run Weka. You will get a screen like the following:
From the Tools menu choose ArffViewer. In the window that opens, choose File→Open and open one of the data files. You should see something like the following (see important note below):
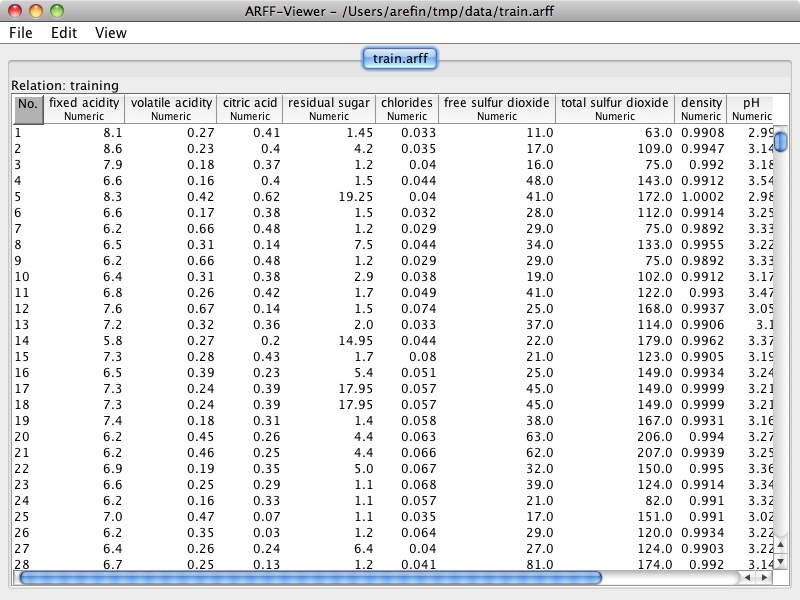
Here you see the same data as in the text editor, but parsed into a spreadsheet-like format. Although you will not need the ArffViewer for this assignment, it is a useful tool to know about when working with Weka. (You can close the ArffViewer window.)
Important Note
You may find that the ARFF files are grayed out and that the All Files option needs to be selected from the File Format dropdown menu for the files to be selectable. However, the ARFF Viewer may still not read the files properly. If such is the case, it is likely that a
.txtextension got appended to the filename when the files were downloaded. However, even if the files are downloaded without.txtgetting appended or an inadvertently added.txtextension is removed, the ARFF Viewer may have trouble reading the files properly. The following steps should resolve the issue:
- View the ARFF in your Web browser by clicking on the link in the instructions or open the downloaded ARFF file in a text editor.
- Copy all the text and paste it to a new text file.
- If you copied the ARFF contents from the downloaded ARFF file, it is recommended that you do not overwrite the downloaded ARFF file when saving the new file on the next step. Instead, delete the downloaded ARFF file.
- Save the new text file with a
.arffextension, carefully making sure that a.txtextension does not get appended.- Open the newly saved ARFF file in the Weka ARFF Viewer to verify the Viewer can display the file in the manner illustrated in the image above.
From the Weka GUI Choose click on the Explorer button to open the
Weka Explorer. The Explorer is the main tool in Weka, and the one you are most
likely to work with when setting up an experiment. For the remainder of this
assignment you will work within the Weka Explorer. The Explorer should open to
the "Preprocess" tab. The Preprocess tab allows you to inspect and
modify your dataset before passing it to a machine learning algorithm. Click
on the button that says "Open file..." and open
train.arff. You should see something like this:
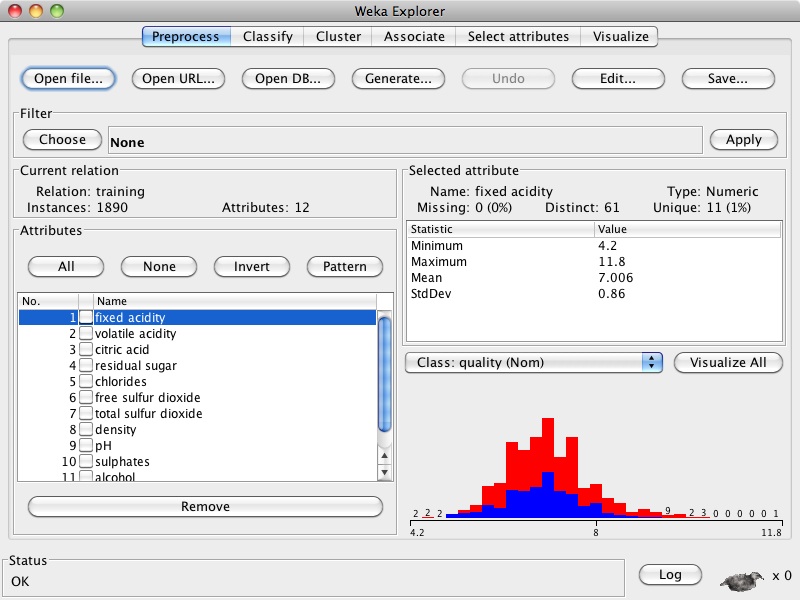
The attributes are listed in the bottom left, and summary statistics for the currently selected attribute are shown on the right side, along with a histogram. Click on each attribute (or use the down arrow key to move through them) and look at the corresponding histogram. You will notice that many numeric attributes have a "hump" shape; this is a common pattern for numeric attributes drawn from real-world data.
You will also notice that some attributes appear to have outliers on one or both sides of the distribution. The proper treatment of outliers varies from one experiment to another. For this assignment you can leave the outliers alone.
In this section you will see how to train a classifier on the data.
Click on the "Classify" tab. Choose ZeroR as the Classifier if it is not already chosen (it is under the "rules" subtree when you click on the "Choose" button). When used in a classification problem, ZeroR simply chooses the majority class. Under "Test options" select "Use training set", then click the "Start" button to run the classifier. You should see something like this:
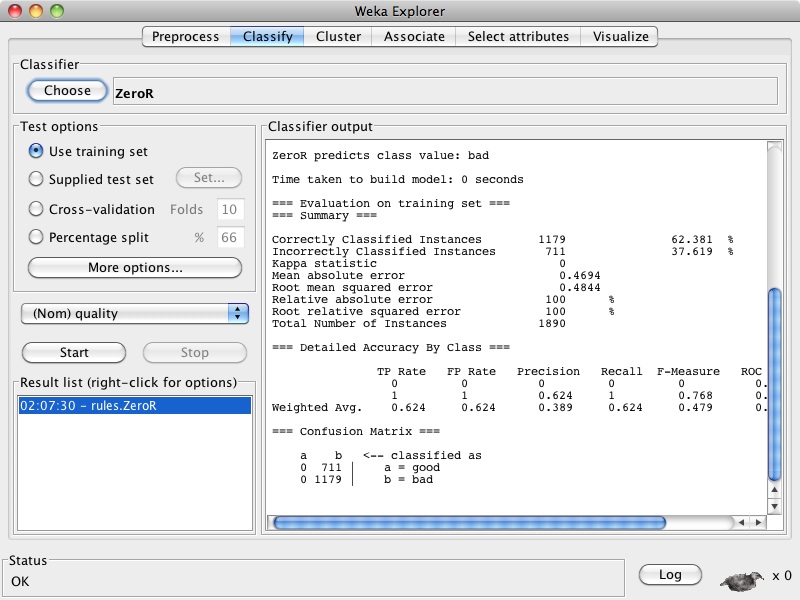
The classifier output pane displays information about the model created by the classifier as well as the evaluated performance of the model. In the Summary section, the row "Correctly Classified Instances" reports the accuracy of the model.
Click on the "Choose" button and select J48 under the "trees" section. Notice that the field to the right of the "Choose" button updates to say "J48 -C 0.25 -M 2". This is a command-line representation of the current settings of J48. Click on this field to open up the configuration dialog for J48:
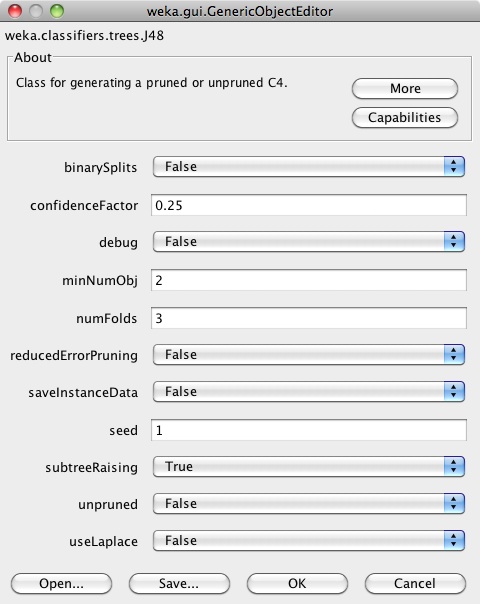
Each classifier has a configuration dialog such as this that shows the parameters of the algorithm as well as buttons at the top for more information. When you change the settings and close the dialog, the command line representation updates accordingly. For now we will use the default settings, so hit "Cancel" to close the dialog.
Under "Test options" select "Use training set", then click the "Start" button to run the classifier. After the classifier finishes, scroll up in the output pane. You should see a textual representation of the generated decision tree.
Scroll back down and record the percentage of Correctly Classified Instances. Now, under "Test options", select "Cross-validation" with 10 folds. Run the classifier again and record the percentage of Correctly Classified Instances.
In both cases, the final model that is generated is based on all of the training data. The difference is in how the accuracy of that model is estimated.
This is the main part of the assignment. Search through the classifiers in Weka and run some of them on the training set. You may want to try varying some of the classifier parameters as well. Choose the one you feel is most likely to generalize well to unseen examples--namely the unlabeled examples in the test set. Feel free to use validation strategies other than 10-fold cross-validation.
When you have built the classifier you want to submit, move on to the following sections.
To export a classifier model you have built:
PS1.model).In order to grade your assignment it must be possible to load your model
file in Weka and run it on a labeled version of
test.arff. You can load your model by right-clicking
in the Result list pane and selecting "Load model".
To generate an ARFF file with predictions for the test data, perform the following steps from within the Classify tab:
test.arff.PS1.arff).
You will now build a classifier for a second data set concerning the evaluation of cars, following which you will answer only the last two questions. (You do not have to answer Questions #1 through #8 again.)
In order to answer the questions, perform the following steps:The car evaluation dataset files are here (see important note below)::
This dataset is adapted from:
Car Evaluation Database, which was derived from a simple hierarchical decision model originally developed for the demonstration of DEX, M. Bohanec, V. Rajkovic: Expert system for decision making. Sistemica 1(1), pp. 145-157, 1990.).
Important Note
The main data file for the car evaluation data set ends in a
.dataextension and has an associated auxiliary data file ending in a.namesextension. However, the usage for the.datafile is the same as for the.arfffile you are already familiar with, including the important note applicable to the wine evaluation data set files, though you have to pay special attention to the following:
- When opening the main data file (
car_train.dataorcar_test.data) in the Weka Explorer, the C4.5 data files (*.data) option needs to be selected from the File Format dropdown menu.- The auxiliary data files (
car_train.namesandcar_test.names) must be located in the same folder as the main data files. (You do not need to take any action on these auxiliary data files other than to keep them in the same folder as the main data files, but inspecting the contents of the files should help you interpret how the main data files work.)
You will perform four experiments, measuring the 10-fold cross-validation accuracy of two types of classifiers (call them classifiers A and B) on two data sets (cars and wine). You can choose A and B however you like -- they can be different classifiers (nearest-neighbor vs. decision trees) or the same classifier with different settings (different numbers of nearest neighbors, for example). Your goal is to choose settings such that the A classifier performs great for wine evaluation, but poorly for car evaluation, and vice-versa for classifier B. In other words, you should strive to find a value as large as you can for the expression below:
wine_acc(A) + car_acc(B) – wine_acc(B) – car_acc(A)
where wine_acc(A) refers to the accuracy of Classifier A on the wine data set, and car_acc(B) refers to the accuracy of Classifier B on the car data set, and so on.
Note: You do not need to obtain the largest possible quantity for the above expression, and it is okay to use classifiers we have discussed in class as long as you can achieve some positive value for the above expression (a value of 2% is sufficient for the assignment).
Note that you will only need to use the training data (car_train.data) for this task. The test data (car_test.data) is provided for your personal reference, should you choose to try your car evaluation classifier on it to gain experience. Therefore, you do not need to perform the steps under Generating Predictions for this task.
Put concise answers to the following questions in a text file, as described in the submission instructions.