We present an approach that estimates missing values in the time-frequency domain of audio signals.
Audio Imputation
By Jinyu Han, Gautham J. Mysore and Bryan Pardo
Work presented at LVA/ICA 2012
Tel-Aviv, Israel
March 12-15, 2012.
Modeling of Audio
Non-negative Spectrogram Factorization (PLCA)
Non-negative spectrogram factorization refers to a class of methods including non-negative matrix factorization and probabilistic latent component analysis (PLCA), which are used to factorize spectrograms. In this discussion, we will use the specific case of PLCA. However, the ideas generalize to most such methods.
One of the problems with PLCA is that:

A Large dictionary learned by PLCA
Non-negative Hidden Markov Model (N-HMM)
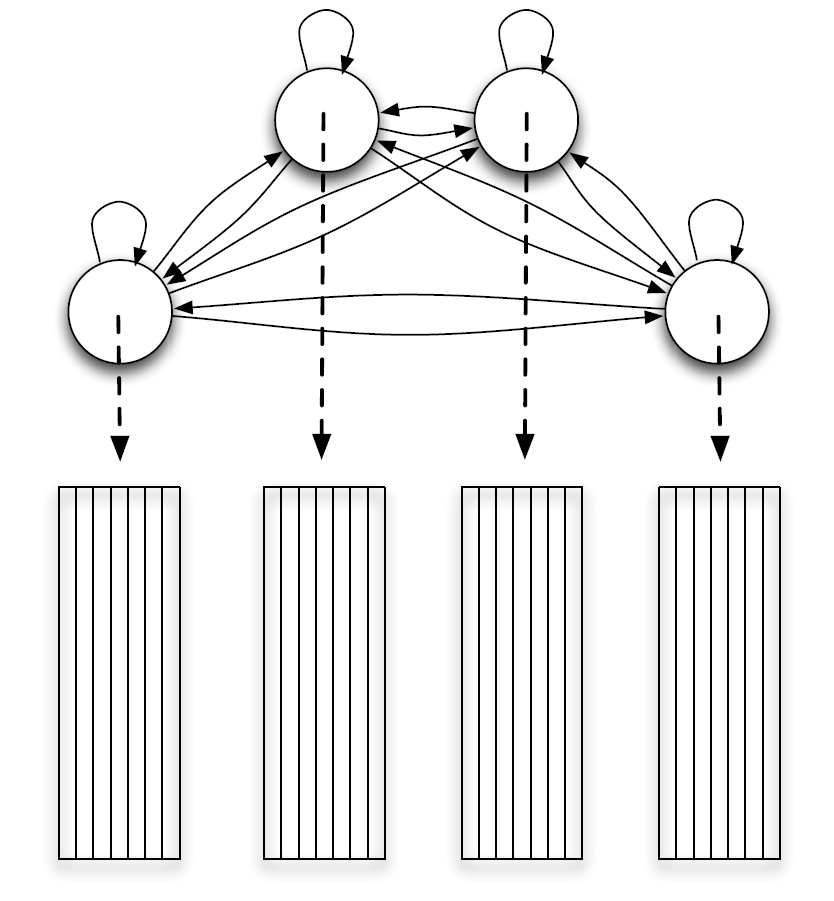
Multiple dictionaries and a Markov chain learned by N-HMM.
An illustration of the proposed audio imputation system using N-HMM (of five states/dictionaries)
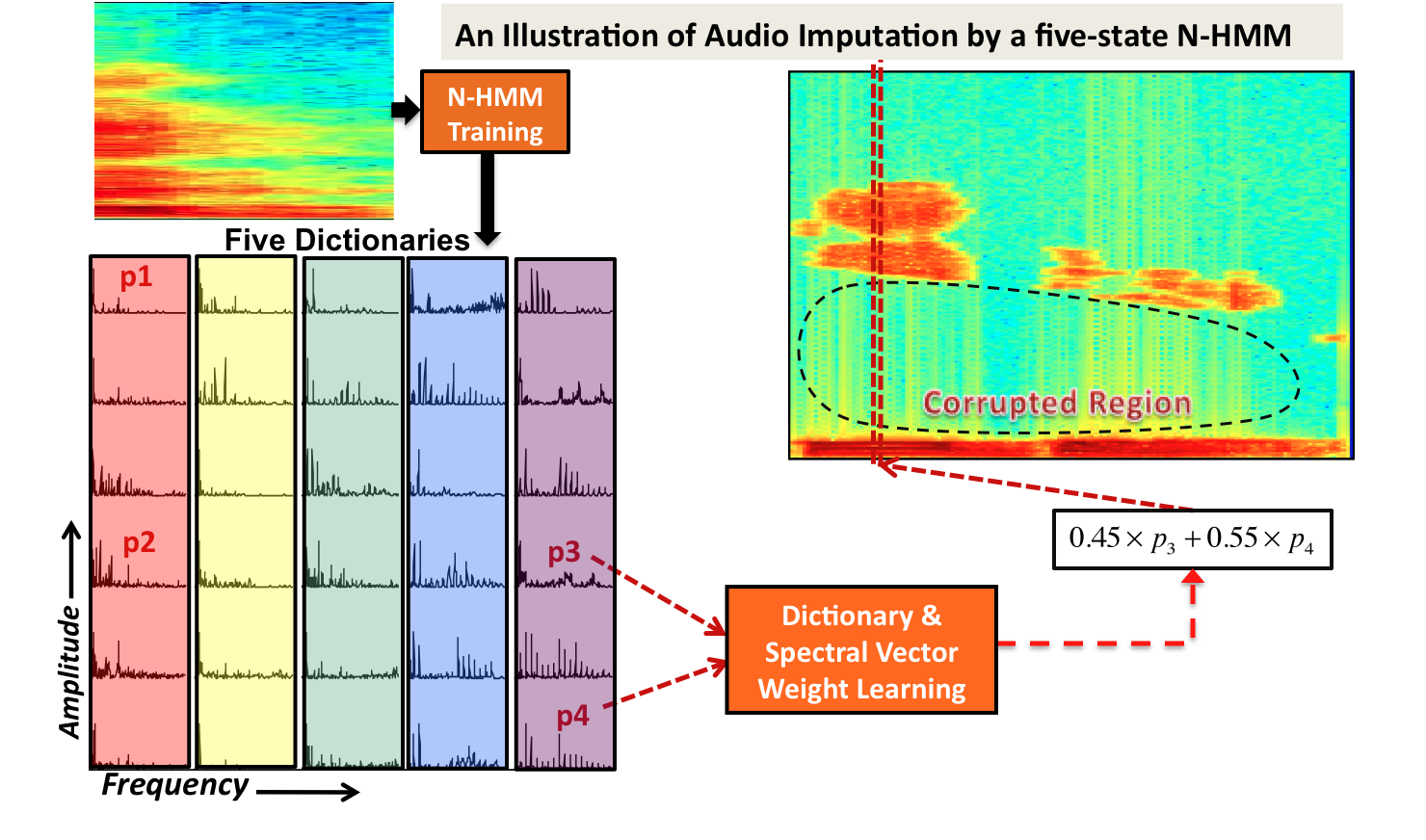
Illustration Examples
In the following examples we automatically fill in the time-frequency domain using our proposed method and compare the results to a method based Probabilistic Latent Component Analysis. Here are two examples with large regions of the spectrogram missing.
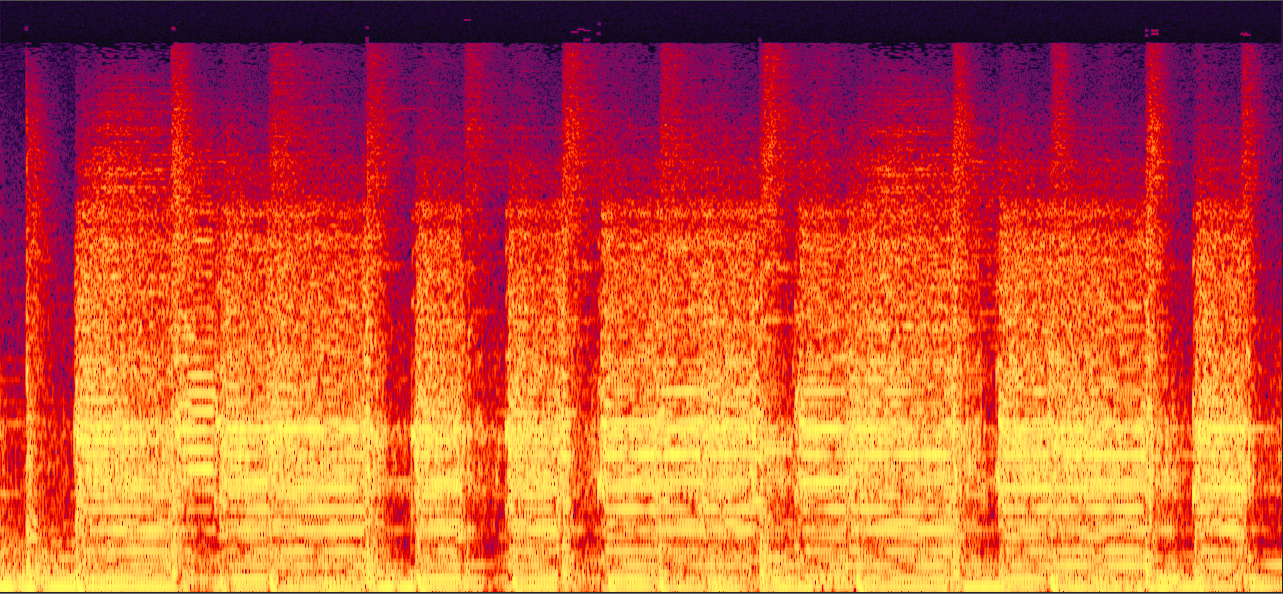
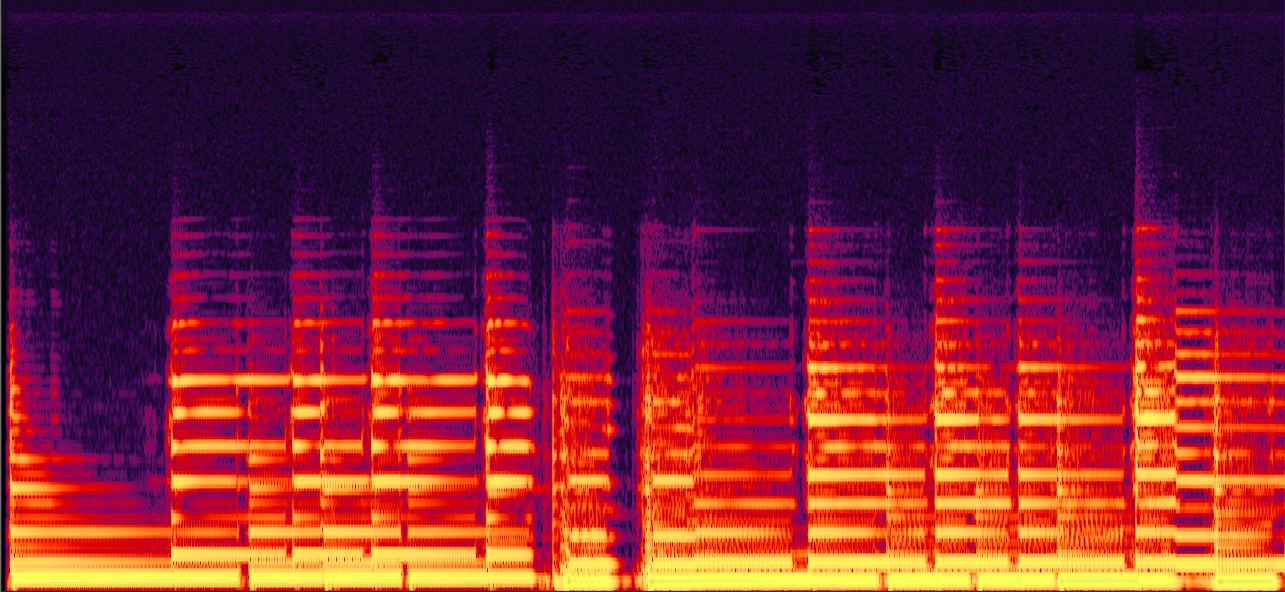
"Scar Tissue" by "Red Hot Chili Peppers"
In this example, PLCA produces a reconstruction with a lots of high frequency noise, while the reconstruction by the proposed method is much more clean. Although the reconstructed signal by the proposed method sounds less full in the high frequency range, we still find that it is more perceptually pleasing than adding extra noise in the high frequency domain
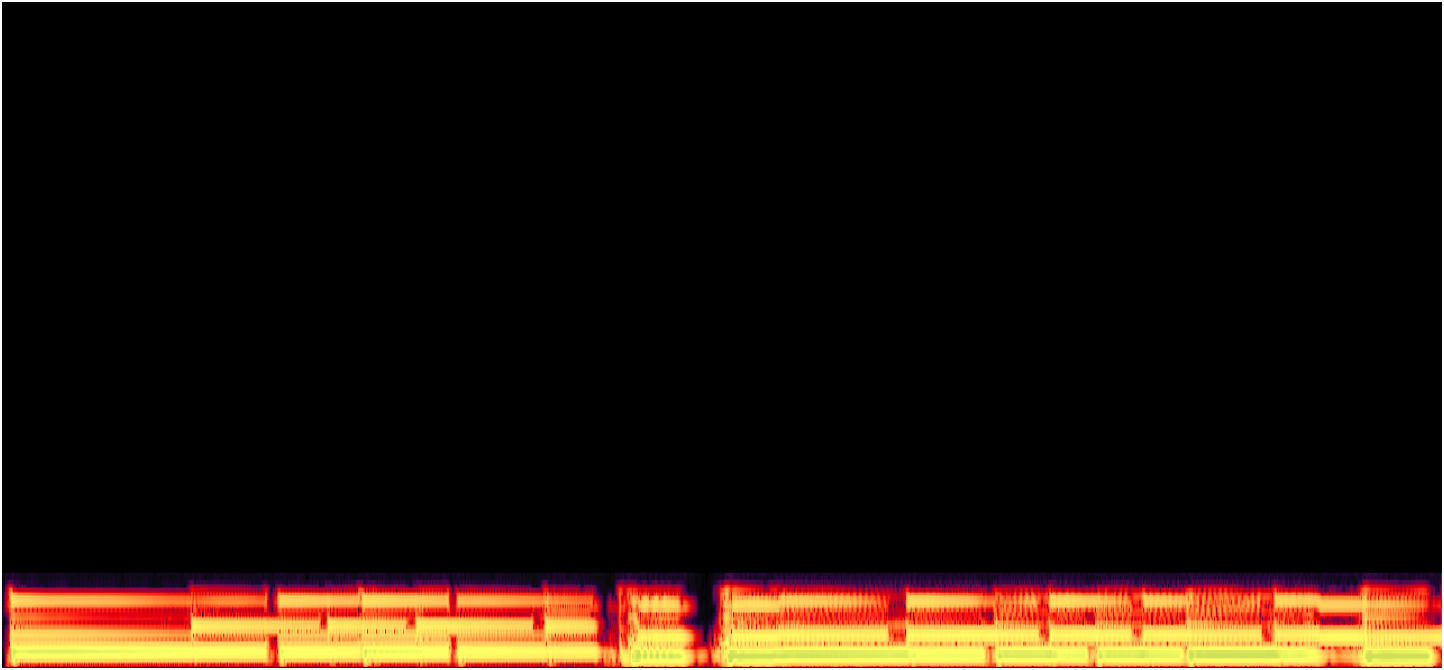
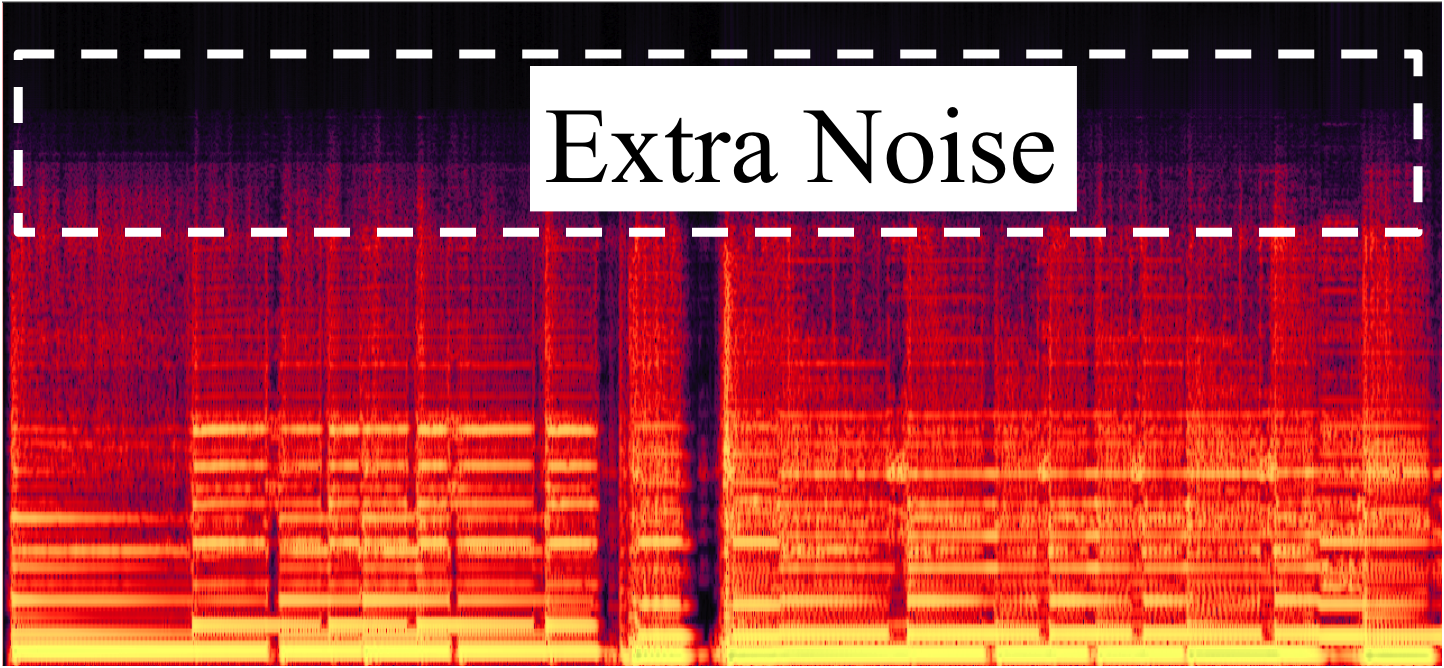
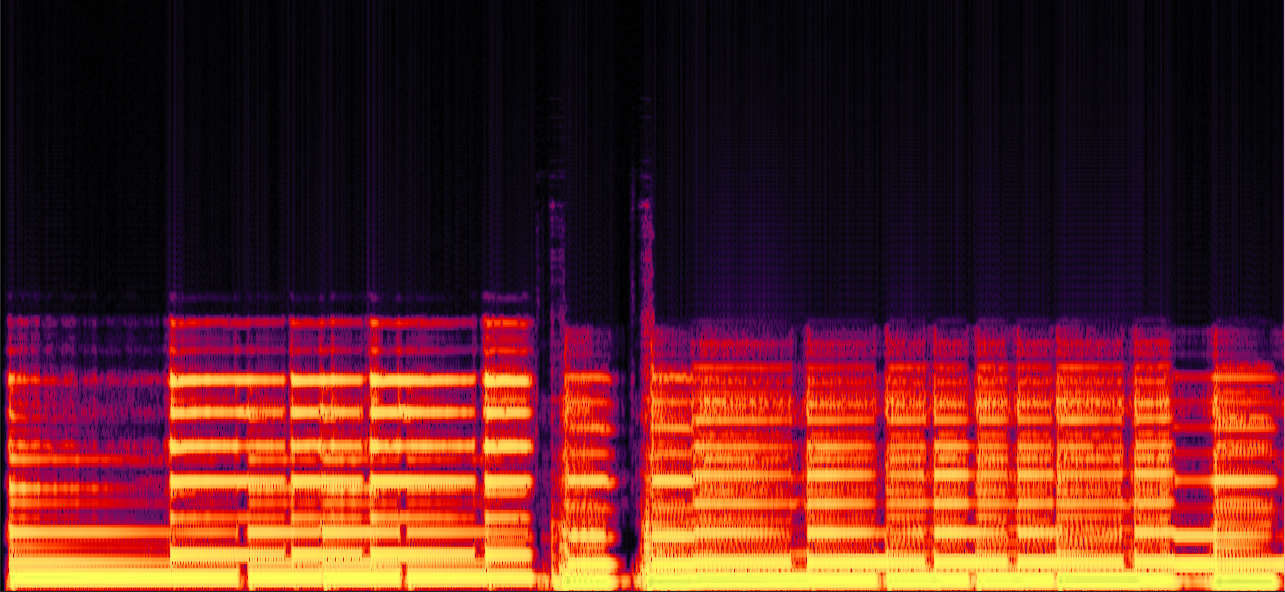
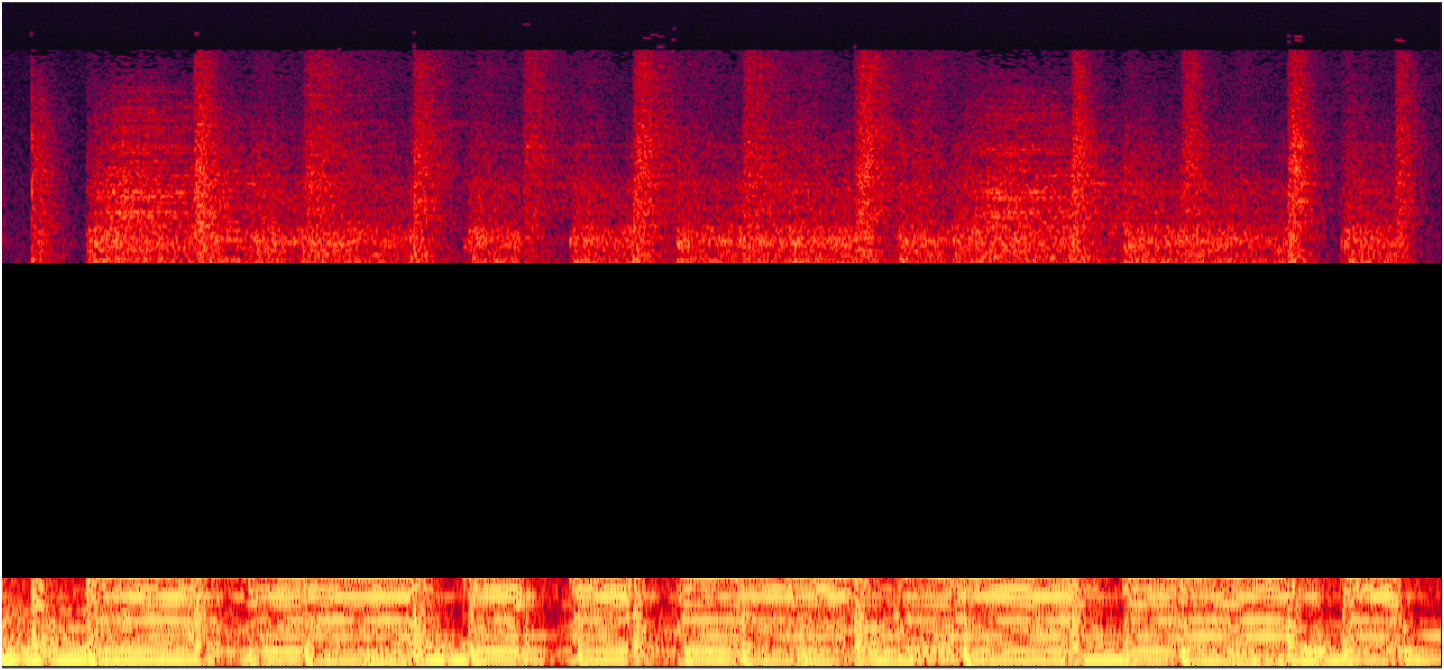
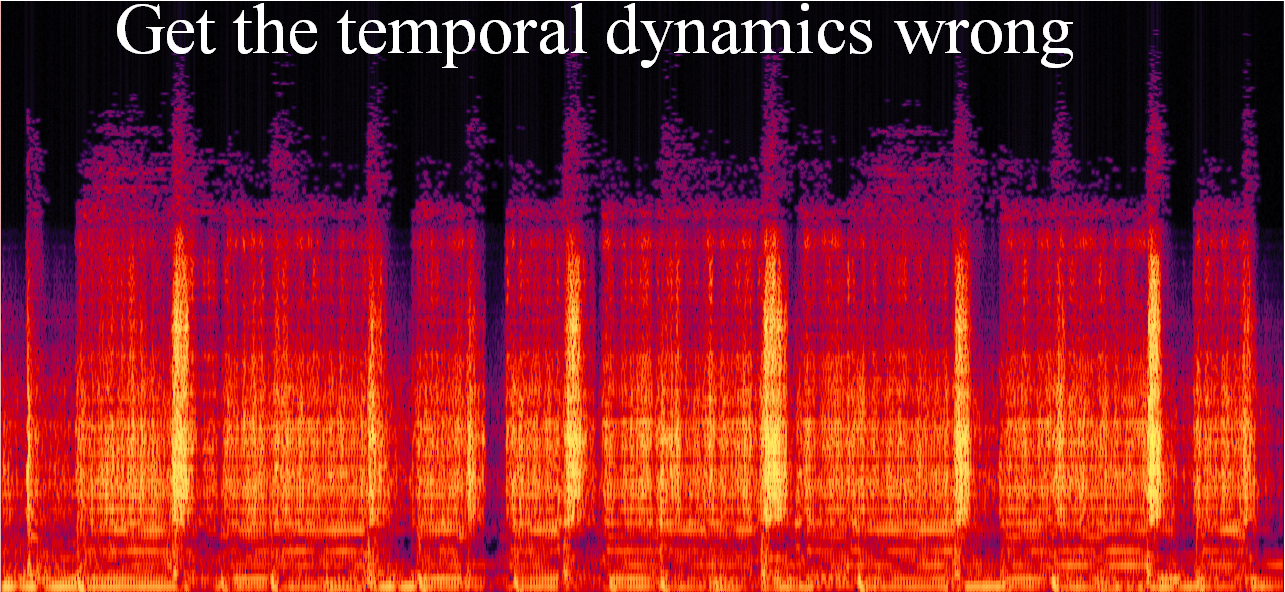
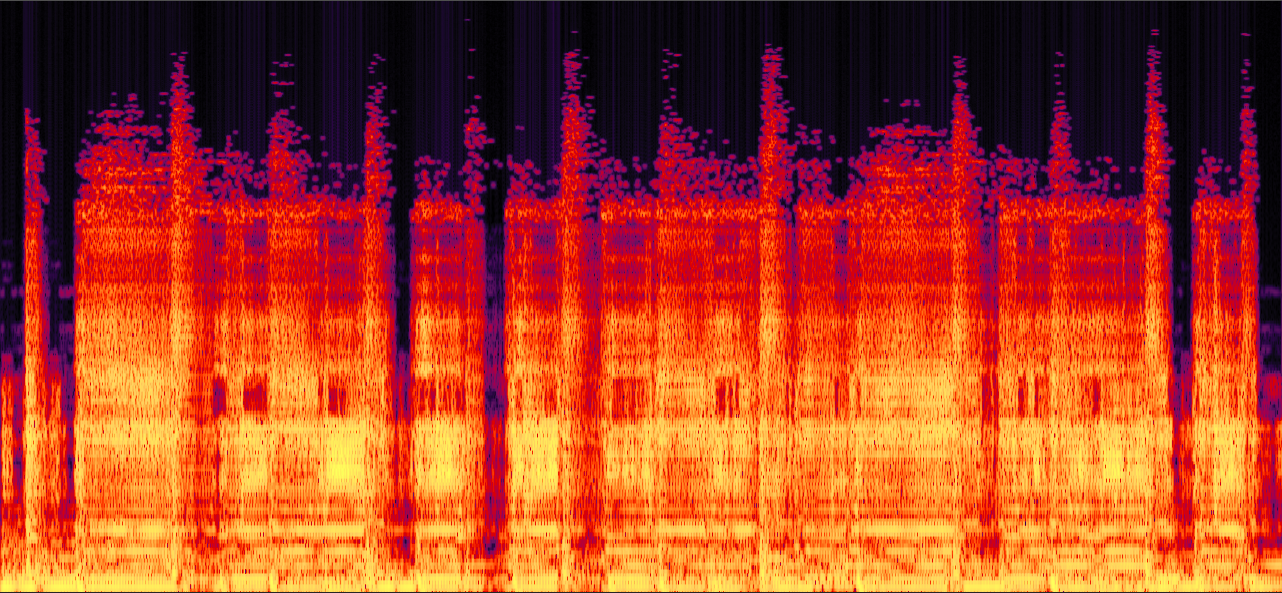
"Born to be wild" by "Steppenwolf"
In this example, PLCA gets the temporal dynamics of the audio wrong. It is obviously to hear that too much energy is asigned to the percussion sound (the bright vertical strip in the spectrogram) in the music. In contrast, the reconstructed signal by our method has a better temporal dynamics.