The Intelligent Classroom
Research: Computer Vision

In order to interact with the speaker effectively, the Intelligent Classroom needs to know where the speaker is and whether he is making any gestures. The classroom has at its disposal a number of advanced computer vision techniques to allow it to gain this information and more. The Classroom is equipped with a number of cameras from which it extracts images that it then examines for salient information. Fortunately, since the Classroom knows what a speaker is likely to do (and often what he is currently doing), it is able to use information about the current situation (the context) to make the computer vision task easier and more accurate.

In general, computer vision is made tractable by using special purpose visual routines that depend on the given context. The Classroom is no exception to this rule. In order to still maintain the flexibility that the Classroom needs as well as the robust accuracy required of the tasks it is put to, the Classroom uses a run-time configurable vision system which we developed, called Gargoyle. Gargoyle provides an environment that can be programmed to take into account the current context for the given situation, and then be quickly reconfigured for a different visual task or context change as the visual situation inside the Classroom changes.
In order to be able to have a visual system that adapts to the given situaltion like this, it must be controlled by a reasoning system which sits on top and reasons about its operation. Each of the visual routines that the Classroom uses has specific information that it can extract from the scene, and specific constraints on when it can operate. In the Classroom this information is explicit, allowing the reasoning system to determine when the different visual routines are appropriate. By selecting different routines to run, we are able to achieve more general purpose vision, as well as more robust vision.
For example, the Classroom could switch routines to acquire different information about where the user is, or what he is doing. Alternatively it might switch routines to acquire the same information in a different way, if the constraints for the first visual routine fail. The result is a system that is able to extract a broad range of information from a scene by focusing on different specific elements as needed by the goals of an execution system it serves.
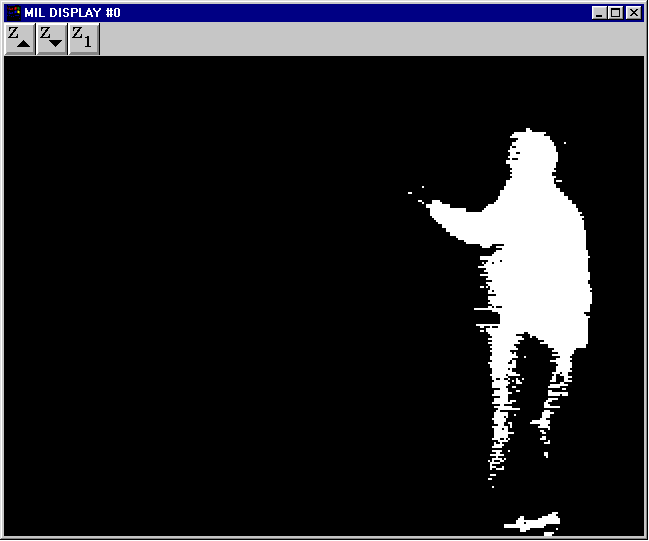
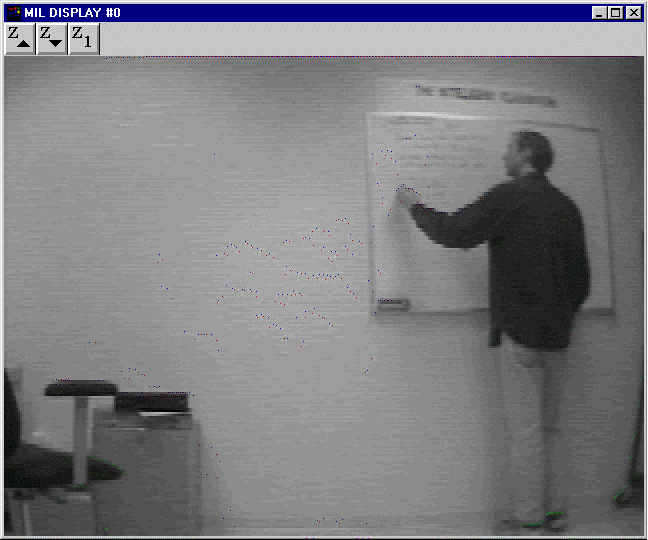
Some example visual routines that the Classroom can currently configure include person tracking and hand drawn icon recognition. There are a number of different methods that the Classroom can use to accomplish these tasks given the current context. For example, in order to track a person in the room, the Classroom can use background subtraction techniques in order to get the segmentation shown. If the person were to wander out of the field of view, it could rapidly reconfigure the pipeline to track by color instead.
By utilizing various visual techniques that are robust in given contexts, the Classroom is able to accomplish a very general vision task. It is only able to accomplish this through reasoning at a higher level about how it is sensing the world.
Maintained by franklin@cs.northwestern.edu
Last update: October 17th, 19102