Research

The
objective of my research is to develop novel approaches to improve
audio analysis, to let people access, manipulate, and enjoy audio more
easily. Below is a list of some of the projects I have worked on over
the past few years:
- Mapping audio concepts to audio tools: an adaptive reverberation tool
- DUET using CQT: stereo source separation adapted to music signals
- REpeating Pattern Extraction Technique (REPET): source separation by repetition
- Audio fingerprinting for cover identification: match a sample from a live performance to its studio version
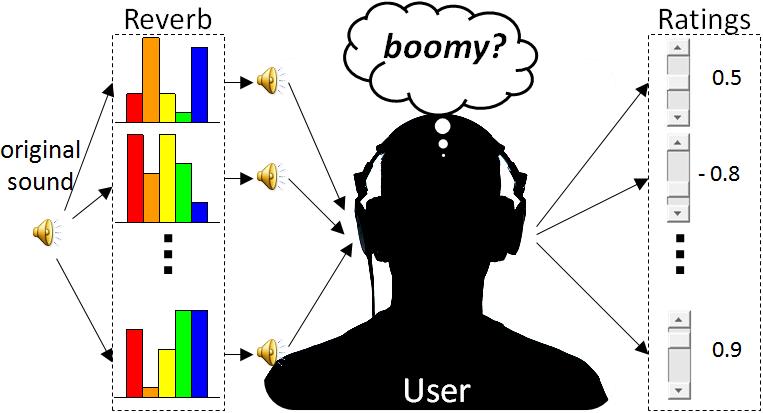
People often think about sound in terms of subjective audio concepts that do not necessarily have a known mapping onto the controls of existing audio tools.
For example, a bass player may wish to use a reverberation tool to make
a recording of her/his bass sound more "boomy"; unfortunately there is
no "boomy" knob. We developed a system that can quickly learn an audio
concept from a user (e.g., a "boomy" effect) and generate a simple
audio controller than can manipulate sounds in terms of that audio
concept (e.g., make a sound more "boomy"), bypassing the bottleneck of
technical knowledge of complex interfaces and individual differences in
subjective terms.
For this
study, we focused on improving on a reverberation tool. To begin with, we developed a reverberator using digital
filters, mapping the parameters of the digital filters to measures
of the reverberation effect, so that the reverberator can
be controlled through meaningful descriptors such as "reverberation time" or "spectral centroid." In the
learning process, a given sound is first modified by a series of
reverberation settings using the reverberator. The user
then listens and rates each modified sound as to how well
it fits the audio concept she/he has in mind. The ratings
are finally mapped onto the controls of the reverberator
and a simple controller is built with which the user will be able to manipulate
the degree of her/his audio concept on a sound. Several
experiments conducted on human subjects showed that the
system learns quickly (under 3 minutes), predicts user
responses well (mean correlation of 0.75), and meets users'
expectations (average human rating of 7.4 out of 10).
A
previous study was conducted based on an equalizer. A
similar system has also been studied with application to
images.
Future research includes the combination of equalization and reverberation tools, the use of new tools
such as compression, the development of plugins, and the
creation of synonym maps based on the commonalities
between different individual concept mappings. More information about this project can also be found on the website of the Interactive Audio Lab.
[pdf] Andrew Todd Sabin, Zafar Rafii,
and Bryan Pardo. "Weighting-Function-Based Rapid Mapping
of Descriptors to Audio Processing Parameters," Journal of the Audio
Engineering Society, 59(6):419--430, June 2011.
[pdf] Zafar Rafii and Bryan Pardo.
"Learning to control a Reverberator using Subjective
Perceptual Descriptors," 10th International Society for Music
Information Retrieval, Kobe, Japan,
October 26-30 2009. (poster)
[pdf] Zafar Rafii and Bryan Pardo. "A
Digital Reverberator controlled through Measures of the
Reverberation," Northwestern University, EECS Department
Technical Report, NWU-EECS-09-08, 2009.
*This work was supported by
National Science Foundation grant number IIS-0757544.
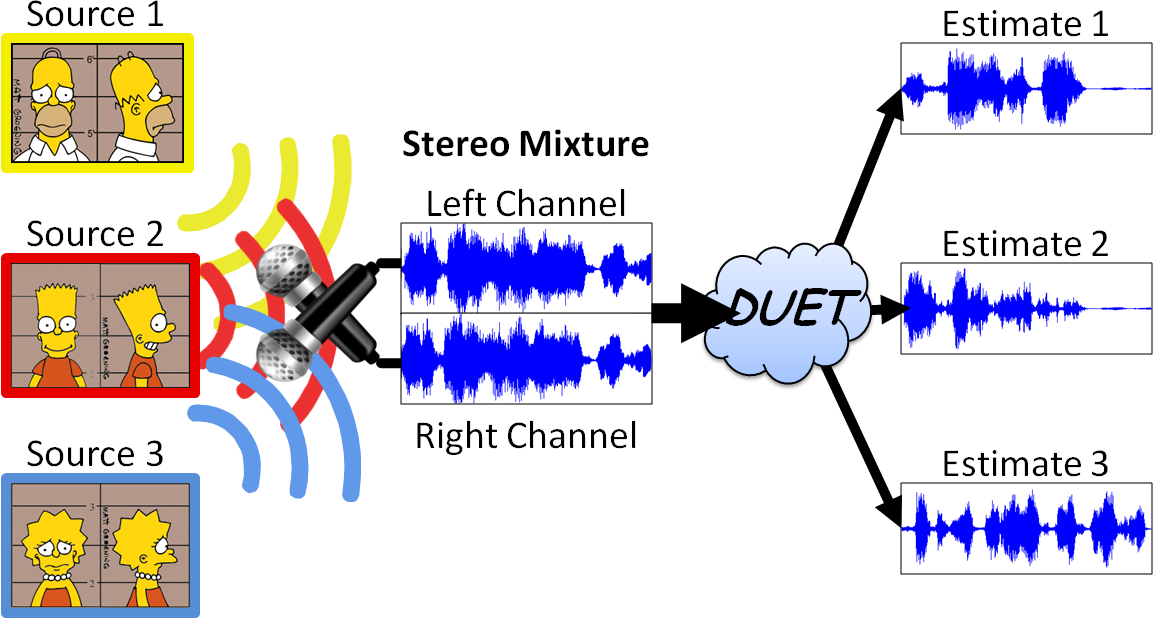
The
Degenerate Unmixing Estimation Technique (DUET) is a blind source separation method that can separate an arbitrary
number of unknown sources using a single stereo mixture.
DUET builds a two-dimensional histogram from the amplitude
ratio and phase difference between channels, where each
peak indicates a source, with peak location corresponding
to the mixing parameters associated with that source.
Provided that the time-frequency bins of the sources do
not overlap too much - an assumption generally validated
by speech mixtures, DUET partitions the time-frequency representation of the
mixture by assigning each bin to the source with the
closest mixing parameters. However, when time-frequency
bins of the sources start overlapping too much - as generally seen in
music mixtures when using the classic Short-Time Fourier
Transform (STFT), peaks start to fuse in the 2d histogram, so
that DUET cannot perform separation effectively.
We
proposed to improve peak/source separation in DUET by
building the 2d histogram from an alternative
time-frequency representation based on the Constant Q
Transform (CQT). Unlike the Fourier Transform, the CQT has
a logarithmic frequency resolution, mirroring the human
auditory system and matching the geometrically spaced
frequencies of the Western music scale, therefore better
adapted to music mixtures. We also proposed other
contributions to enhance DUET, such as adaptive
boundaries for the 2d histogram to improve peak resolving
when sources are spatially too close to each other, and Wiener filtering
to improve source reconstruction. Experiments on mixtures
of piano notes and harmonic sources showed that
peak/source separation is overall improved, especially at
low octaves (under 200 Hz) and for small mixing angles
(under pi/6 rad). Experiments on mixtures of female and male
speech showed that the use of CQT gives equally good
results.
Unlike
the classic DUET based on the Fourier Transform, DUET
combined with the CQT can resolve adjacent pitches in low
octaves as well as in high octaves thanks to the log
frequency resolution of the CQT:
[mp3] Mixture of 3 piano notes:
A2, Bb2, and B2
[mp3] 1. Original
A2
[mp3] 1. Estimated
A2
[mp3] 2. Original
Bb2 [mp3] 2. Estimated
Bb2
[mp3] 3. Original
B2
[mp3] 3. Estimated
B2
DUET
combined with the CQT and adaptive boundaries helps to
improve separation when sources have low pitches (for
example here between the two cellos) and/or are spatially
too close to each other:
[mp3] Mixture of 4 harmonic sources
[mp3] 1. Original
cello 1 [mp3] 1. Estimated
cello 1
[mp3] 2. Original
cello 2 [mp3] 2. Estimated
cello 2
[mp3] 3. Original
flute [mp3] 3. Estimated
flute
[mp3] 4. Original
strings
[mp3] 4. Estimated
strings
More information about this project can also be found on the website of the Interactive Audio Lab.
[pdf] Zafar Rafii and Bryan Pardo. "Degenerate Unmixing Estimation Technique using the Constant Q Transform," 36th International Conference on Acoustics, Speech and Signal Processing, Prague, Czech Republic, May 22-27 2011. (poster)
*This work was supported by
National Science Foundation grant numbers IIS-0757544 and IIS-0643752.
This is my thesis work; please see the REPET tab.
Suppose
that you are at a music festival checking on an artist, and you would
like to quickly know about the song that is being played (e.g., title,
lyrics, album, etc.). If you have a smartphone, you could record a
sample of the live performance and compare it against a database of
existing recordings from the artist. Services such as Shazam or
SoundHound will not work here, as this is not the typical framework for
audio fingerprinting or query-by-humming systems, as a live performance
is neither identical to its studio version (e.g., variations in
instrumentation, key, tempo, etc.) nor it is a hummed or sung melody.
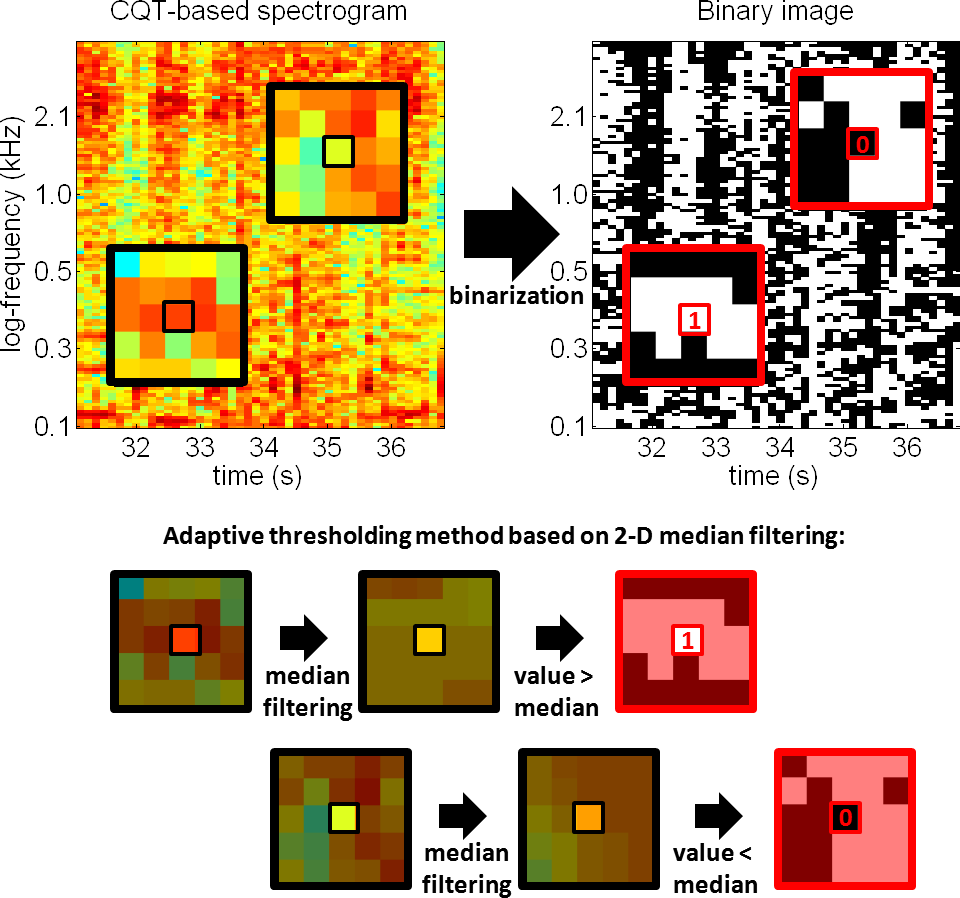
We propose an audio fingerprinting system that can deal with live version identification by using image processing techniques.
Compact fingerprints are derived using a log-frequency spectrogram and
an adaptive thresholding method, and template matching is performed
using the Hamming similarity and the Hough Transform.
[pdf] Zafar Rafii, Bob Coover, and Jinyu Han. “An Audio Fingerprinting System for Live Version Identification using Image Processing Techniques,” 39th International Conference on Acoustics, Speech and Signal Processing, Florence, Italy, May 4-9 2014. (poster)
*This work was performed during an internship at Gracenote, a leading company in music and video recognition.