REPET
Repetition is a fundamental element in generating and perceiving structure. In audio, mixtures are often composed of structures where a repeating background signal is superimposed with a varying foreground signal (e.g., a singer overlaying varying vocals on a repeating accompaniment or a varying speech signal mixed up with a repeating background noise). On this basis, we present the REpeating Pattern Extraction Technique (REPET), a simple approach for separating the repeating background from the non-repeating foreground in an audio mixture. The basic idea is to find the repeating elements in the mixture, derive the underlying repeating models, and extract the repeating background by comparing the models to the mixture. Unlike other separation approaches, REPET does not depend on special parametrizations, does not rely on complex frameworks, and does not require external information. Because it is only based on repetition, it has the advantage of being simple, fast, blind, and therefore completely and easily automatable. More information about this project can also be found on the website of the Interactive Audio Lab.
- Original REPET: the original method
- Adaptive REPET: an extension that can handle varying repeating structures
- REPET-SIM: a generalization that can handle non-periodically repeating structures
- uREPET:
a user interface system that identifies and recover patterns repeating
in time and frequency (REVIEWERS FOR ICASSP 2015, PLEASE FOLLOW THIS
LINK)
- Codes: source codes
- Publications: related publications
The original REPET aims at identifying and extracting the repeating patterns in an audio mixture, by estimating a period of the underlying repeating structure and modeling a segment of the periodically repeating background.
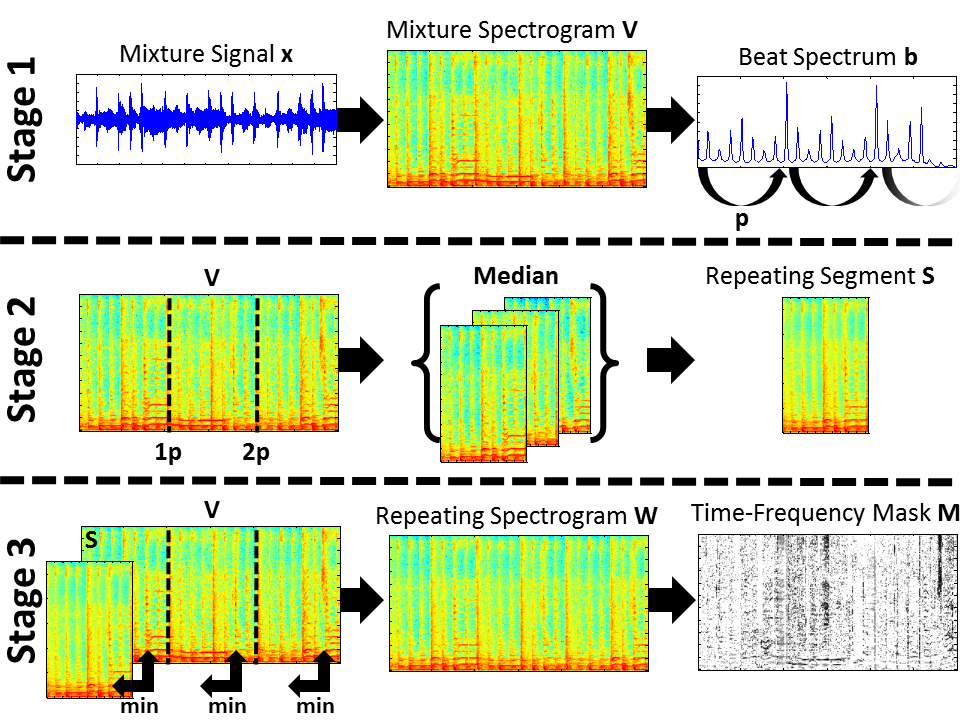
Fig. 1. Overview of the original REPET. Stage 1: calculation of the beat spectrum b and estimation of a repeating period p. Stage 2: segmentation of the mixture spectrogram V and calculation of the repeating segment S. Stage 3: calculation of the repeating spectrogram W and derivation of the time-frequency mask M.
Experiments on a data set of song clips showed that the original REPET can be effectively applied for music/voice separation. Experiments showed that REPET can also be combined with other methods to improve background/foreground separation; for example, it can be used as a preprocessor to pitch detection algorithms to improve melody extraction, or as a postprocessor to a singing voice separation algorithm to improve music/voice separation.
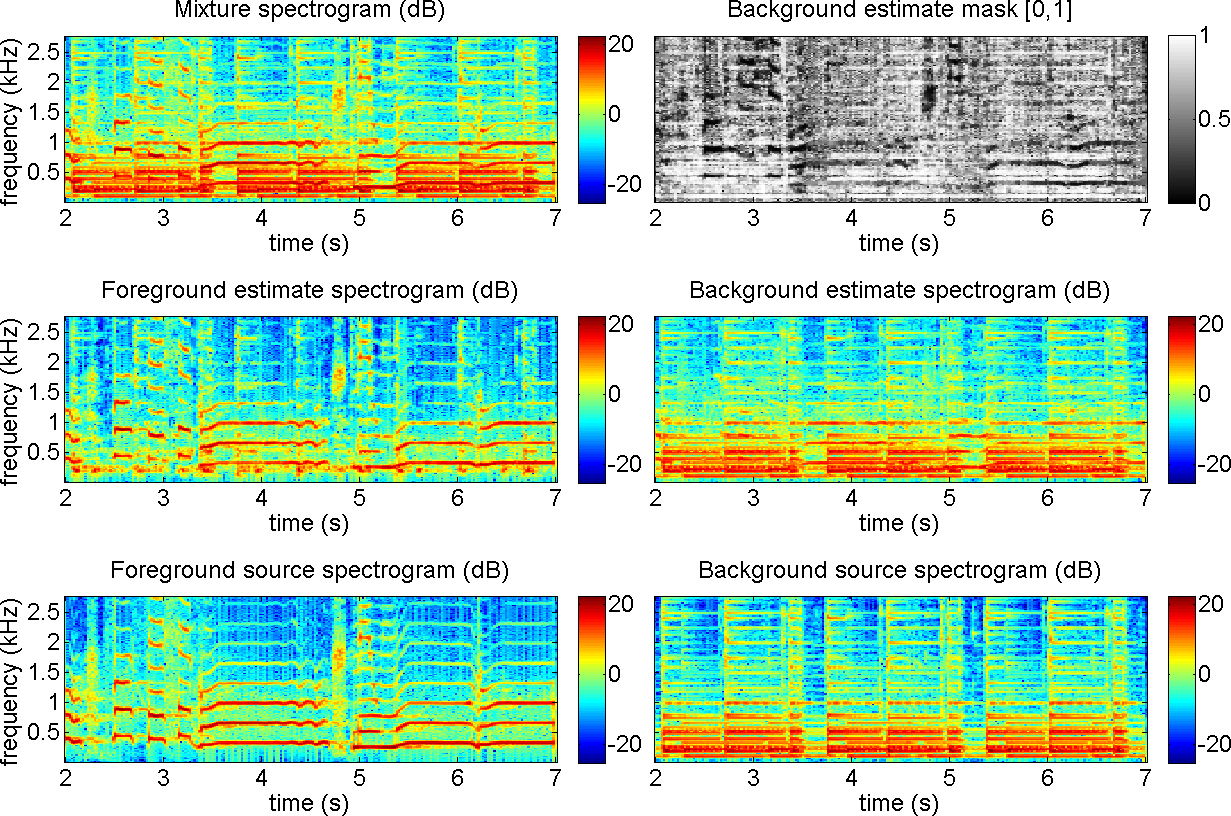
Fig. 2.
Music/voice separation using the original REPET. The mixture is a
female singer (foreground) singing over a guitar accompaniment
(background). The guitar has a repeating chord progression that is
stable along the song. The spectrograms and the mask are shown for 5
seconds and up to 2.5 kHz. The file is Tamy - Que Pena Tanto Faz from the task of professionally produced music recordings of the Signal Separation Evaluation Campaign (SiSEC).
[wav] Tamy - Que Pena Tanto Faz (13 second excerpt)
[wav] Foreground estimate [wav] Background estimate
[wav] Foreground source [wav] Background source
The original REPET can be easily extended to handle varying repeating structures, by simply applying the method along time, on individual segments or via a sliding window. Experiments on a data set of full-track real-world songs showed that this method can be effectively applied for music/voice separation. Experiments also showed that there is a trade-off for the window size in REPET: if the window is too long, the repetitions will not be sufficiently stable; if the window is too short, there will not be sufficient repetitions.
The original REPET works well when the repeating background is relatively stable (e.g., a verse or the chorus in a song); however, the repeating background can also vary over time (e.g., a verse followed by the chorus in the song). The adaptive REPET is an extension of the original REPET that can handle varying repeating structures, by estimating the time-varying repeating periods and extracting the repeating background locally, without the need for segmentation or windowing.
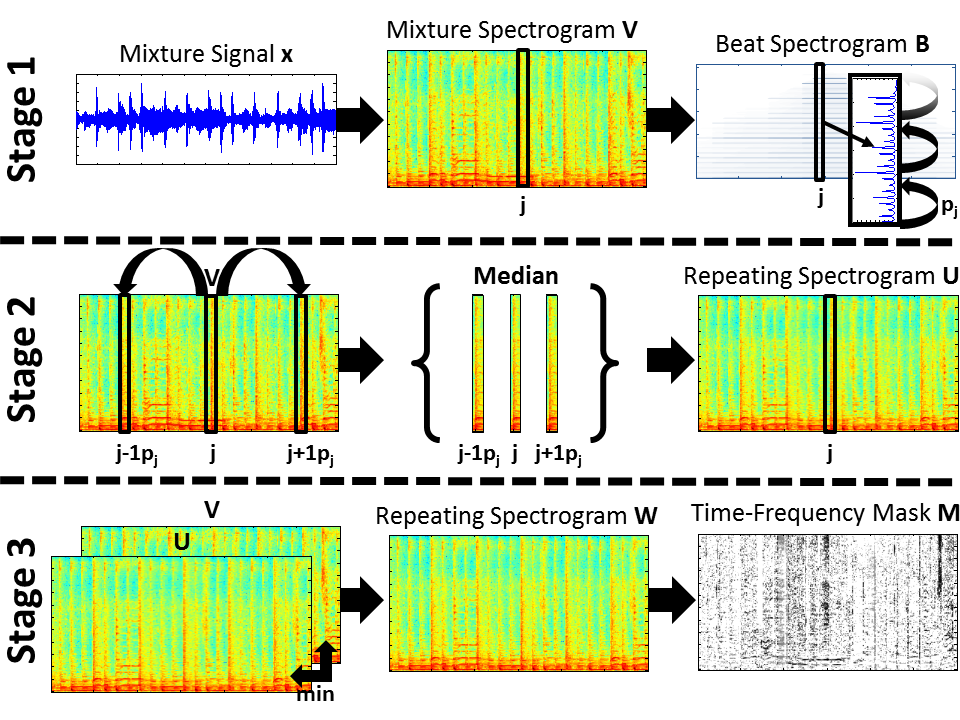
Fig. 3. Overview of the adaptive REPET. Stage 1: calculation of the beat spectrogram B and estimation of the repeating periods pj’s. Stage 2: filtering of the mixture spectrogram V and calculation of an initial repeating spectrogram U. Stage 3: calculation of the refined repeating spectrogram W and derivation of the time-frequency mask M.
Experiments on a data set of full-track real-world songs showed that the adaptive REPET can be effectively applied for music/voice separation.
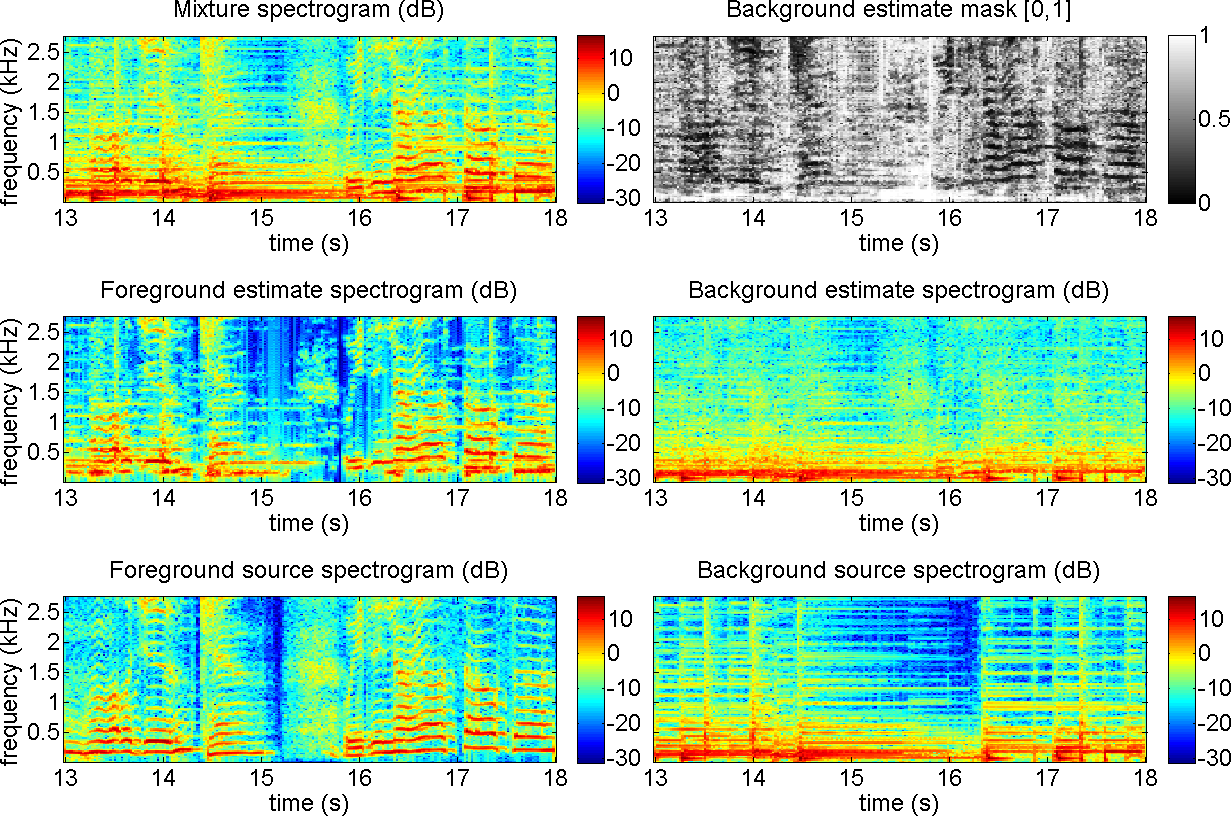
Fig. 4.
Music/voice separation using the adaptive REPET. The mixture is a male
singer (foreground) singing over a guitar and drums accompaniment
(background). The guitar has a repeating chord progression that changes
around 15 seconds. The spectrograms and the mask are shown for 5
seconds and up to 2.5 kHz. The file is Another Dreamer - The Ones We Love from the task of professionally produced music recordings of the Signal Separation Evaluation Campaign (SiSEC).
[wav] Another Dreamer - The Ones We Love (25 second excerpt)
[wav] Foreground estimate [wav] Background estimate
[wav] Foreground source [wav] Background source
The REPET methods work well when the repeating background has periodically repeating patterns (e.g., jackhammer noise); however, the repeating patterns can also happen intermittently or without a global or local periodicity (e.g., frogs by a pond). REPET-SIM is a generalization of REPET that can also handle non-periodically repeating structures, by using a similarity matrix to identify the repeating elements.
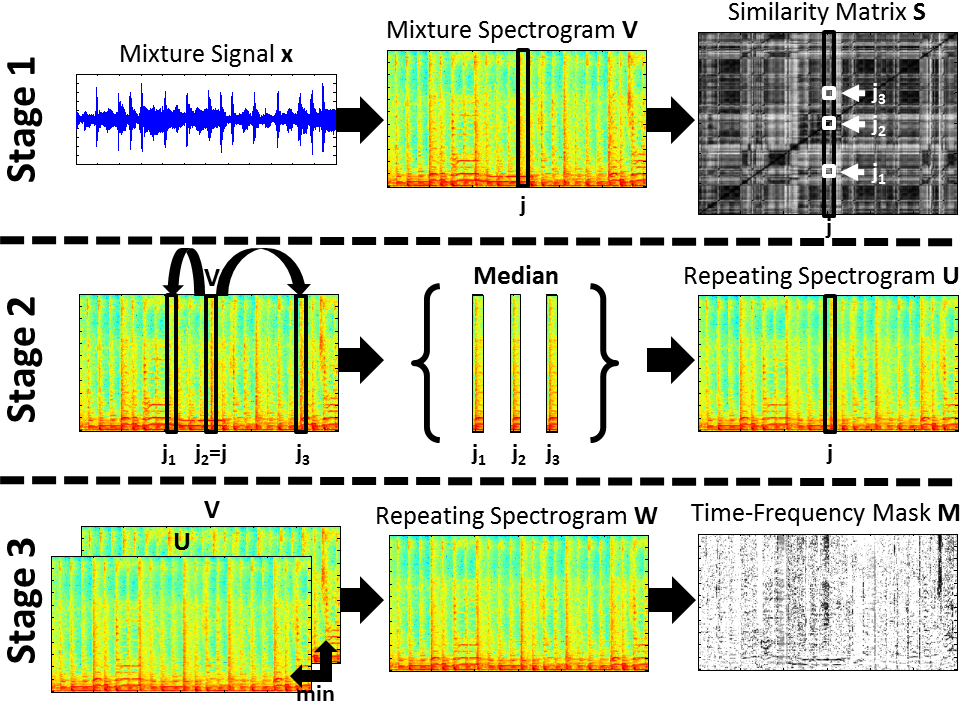
Fig. 5. Overview of REPET-SIM. Stage 1: calculation of the similarity matrix S and estimation of the repeating indices jk’s. Stage 2: filtering of the mixture spectrogram V and calculation of an initial repeating spectrogram U. Stage 3: calculation of the refined repeating spectrogram W and derivation of the time-frequency mask M.
Experiments on a data set of full-track real-world songs showed that REPET-SIM can be effectively applied for music/voice separation.
REPET-SIM can be easily implemented online to handle real-time computing, particularly for real-time speech enhancement. The online REPET-SIM simply processes the time frames of the mixture one after the other given a buffer that temporally stores past frames. Experiments on a data set of two-channel mixtures of one speech source and real-world background noise showed that the online REPET-SIM can be effectively applied for real-time speech enhancement.
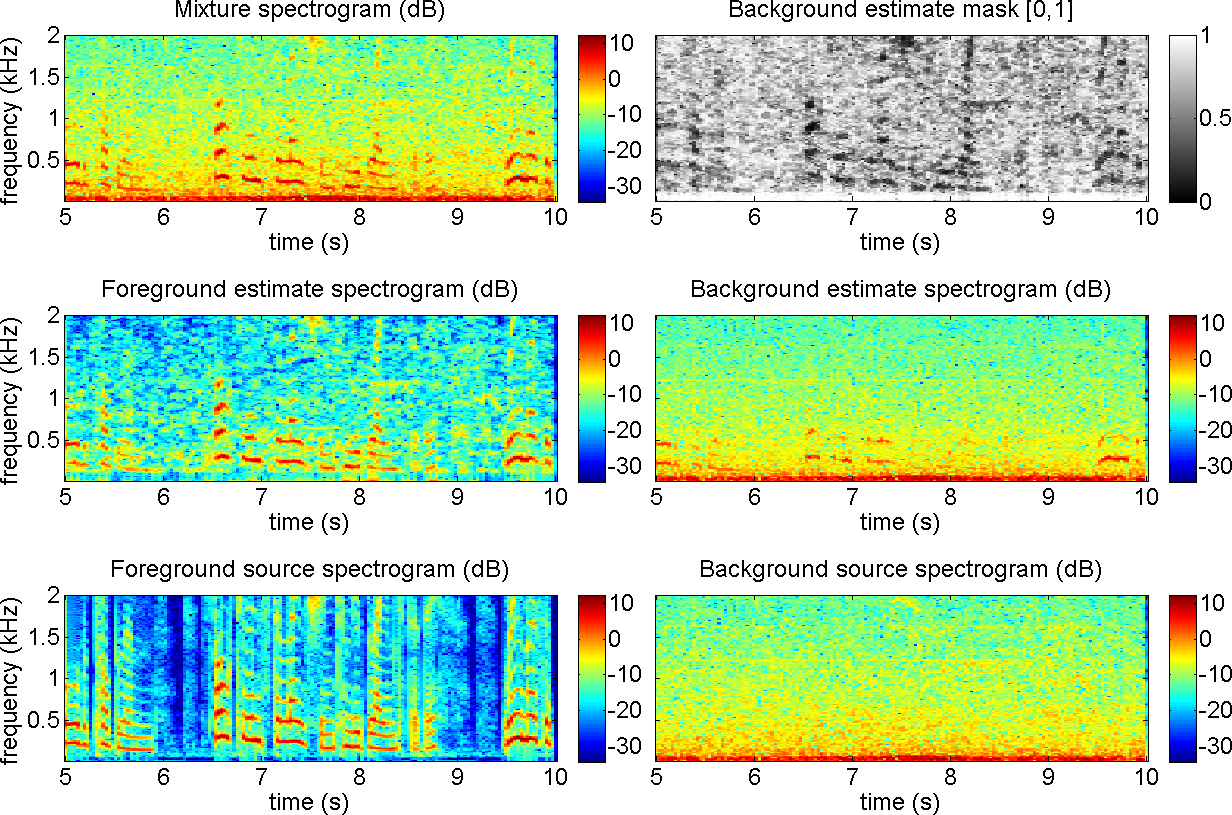
Fig. 6.
Noise/speech separation using REPET-SIM. The mixture is a female
speaker (foreground) speaking in a town square (background). The square
has repeating noisy elements (passers-by and cars) that happen
intermittently. The spectrograms and the mask are shown for 5 seconds
and up to 2 kHz. The file is dev_Sq1_Co_B
from the task of two-channel mixtures of speech and real-world
background noise of the Signal Separation Evaluation Campaign (SiSEC)
[wav] dev_Sq1_Co_B (10 second excerpt)
[wav] Foreground estimate [wav] Background estimate
[wav] Foreground source [wav] Background source
Repetition is a fundamental element in generating and perceiving structure in audio. Especially in music, structures tend to be composed of patterns that repeat through time (e.g., rhythmic elements in a musical accompaniment), and also frequency (e.g., different notes of the same instrument). The auditory system has the remarkable ability to parse such patterns by identifying repetitions within the audio mixture. On this basis, we propose a simple user interface system for recovering patterns repeating in time and frequency in mixtures of sounds. A user selects a region in the log-frequency spectrogram of an audio recording from which she/he wishes to recover a repeating pattern covered by an undesired element (e.g., a note covered by a cough). The selected region is then cross-correlated with the spectrogram to identify similar regions where the underlying pattern repeats. The identified regions are finally averaged over their repetitions and the repeating pattern is recovered.
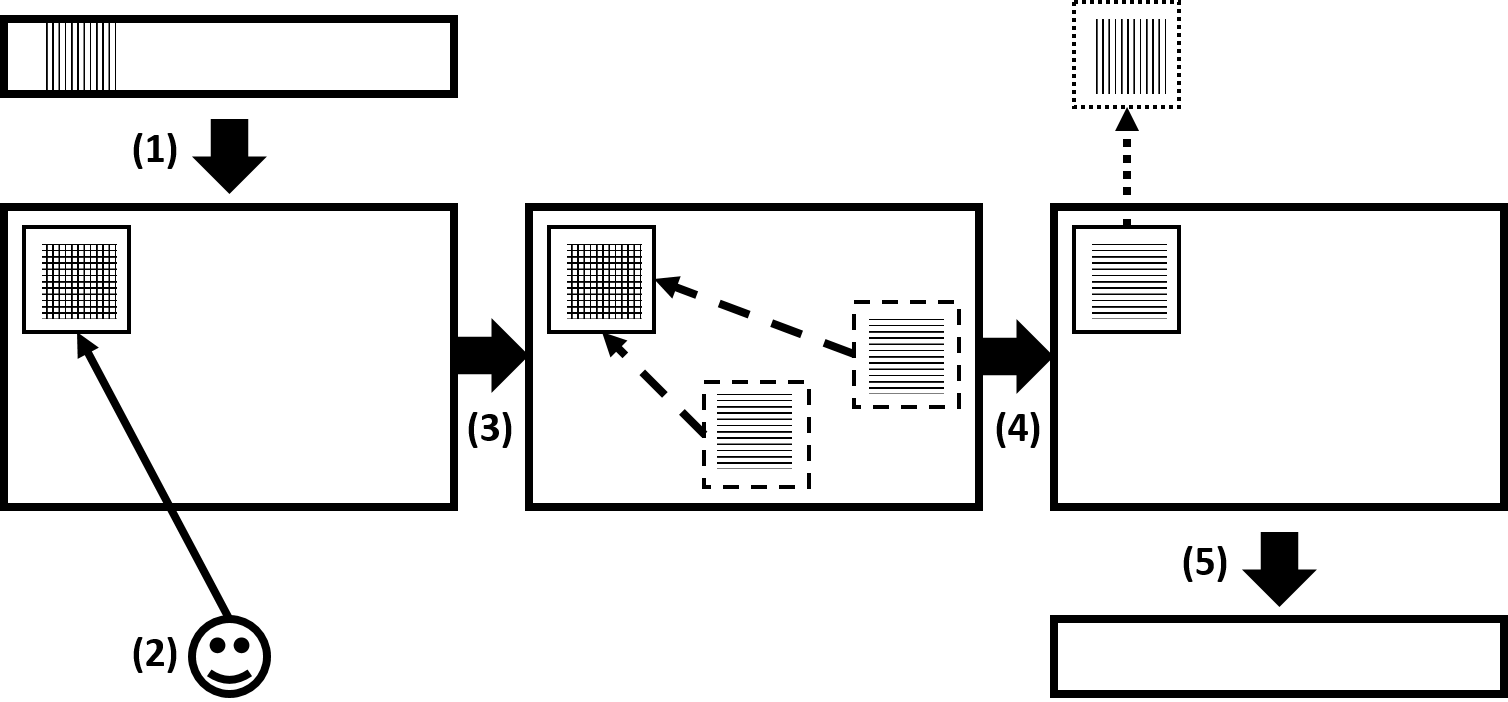
Fig. 7.
Overview of the system. (1) An audio recording with an undesired
element is transformed into a log-frequency spectrogram. (2) The user
selects the region of the undesired element in the spectrogram. (3) The
selected region is cross-correlated with the spectrogram to identify
similar regions where the underlying pattern repeats. (4) The
identified regions are averaged over their repetitions and the repeating
pattern is recovered. (5) The filtered spectrogram is inverted back to the time-domain with the undesired element removed.
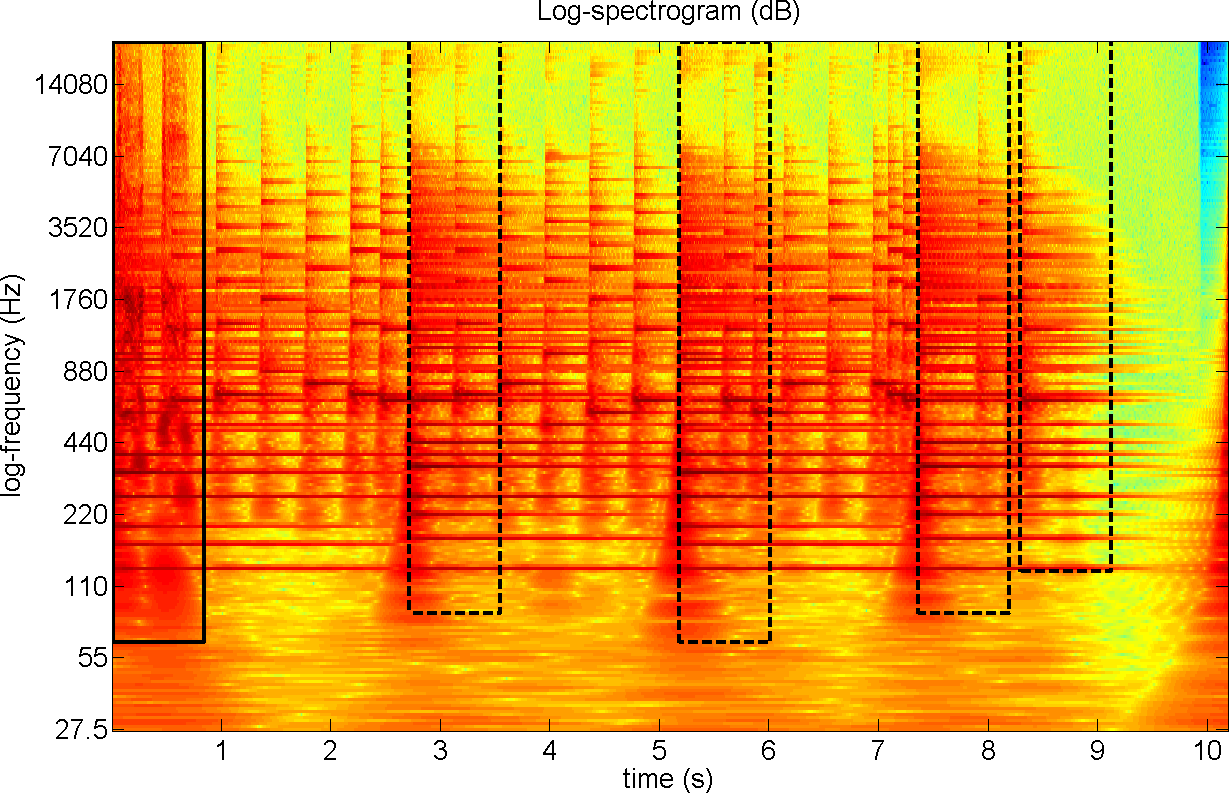
Fig. 8.
Log-spectrogram of a melody with a cough covering the first note. The
user selected the region of the cough (solid line) and the system
identified similar regions where the underlying note repeats (dashed
lines).
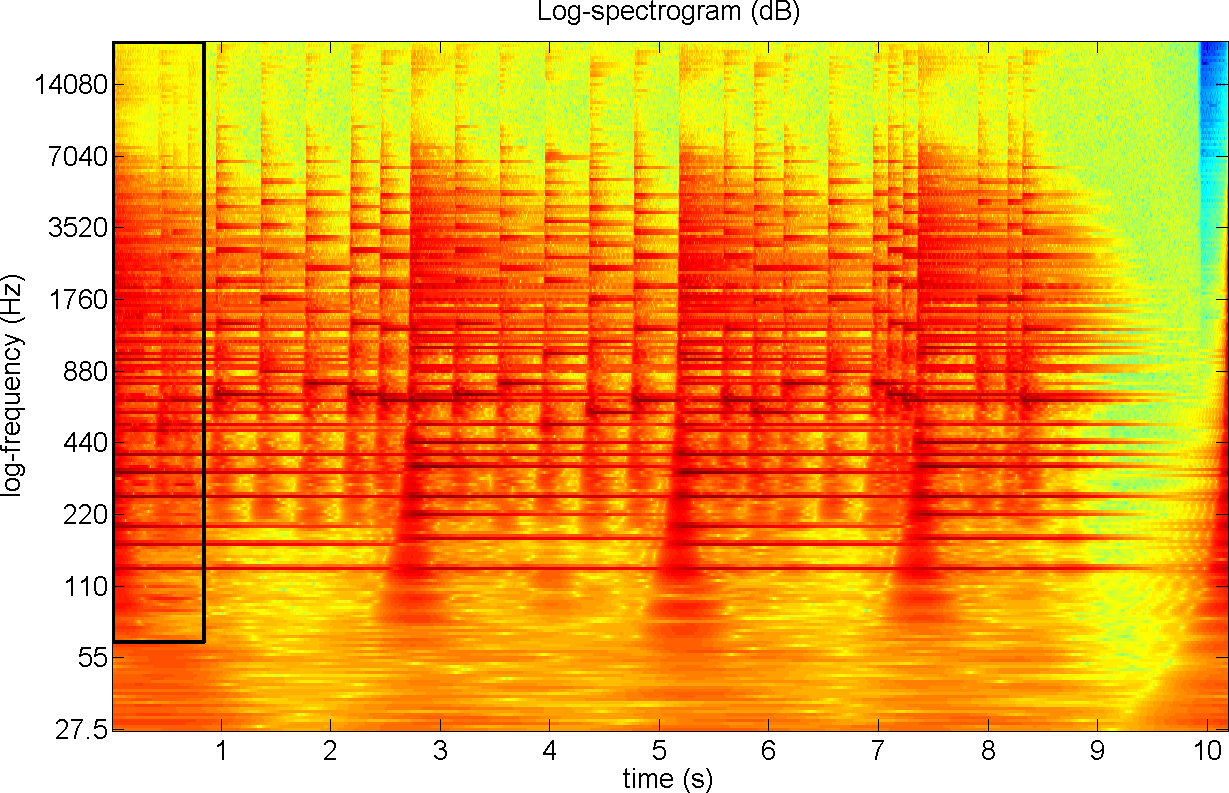
Fig. 9.
Log-spectrogram of the melody with the first note recovered. The system
averaged the identified regions over their repetitions and filtered out
the cough from the selected region.
[wav] melody covered by a cough
[wav] recovered melody: SDR=8.7 dB, SIR=13.4 dB, SAR=13.6 dB (for the recovered note)
[wav] original melody
[wav] original cough
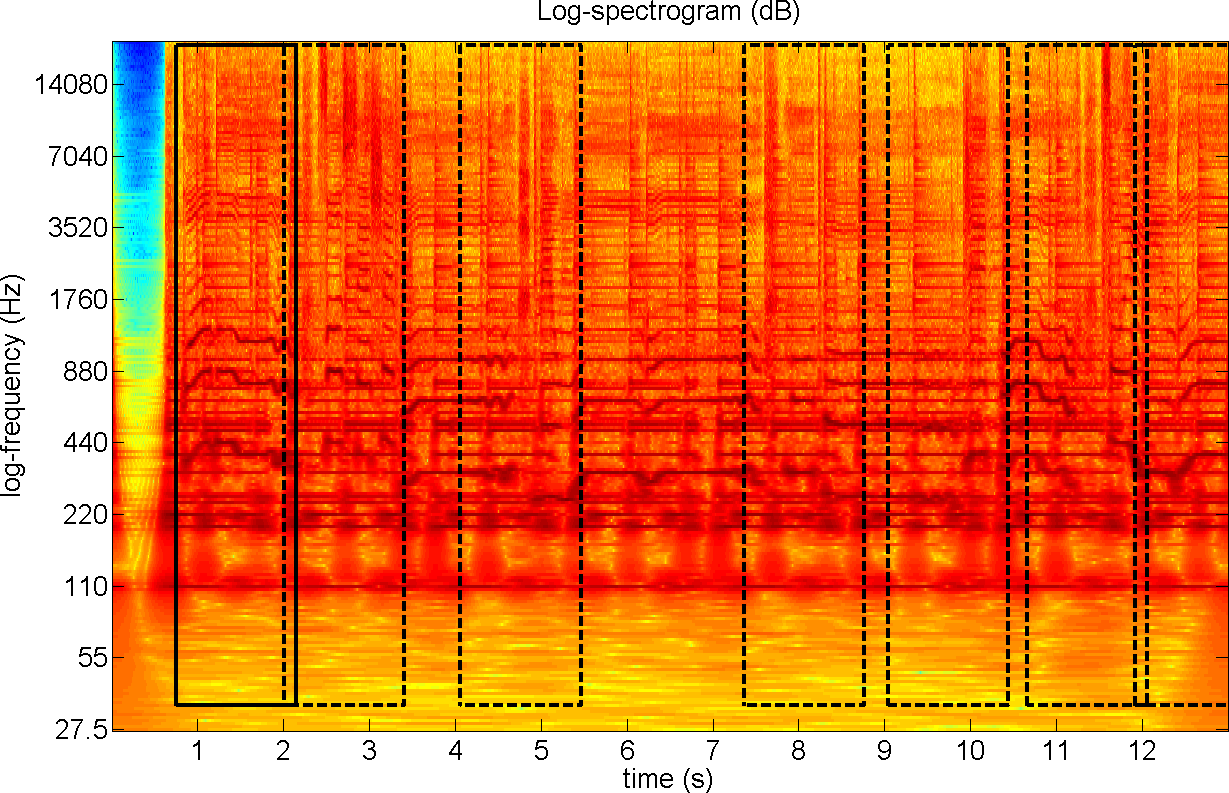
Fig. 10.
Log-spectrogram of a song with vocals covering an accompaniment. The
user selected the region of the first measure (solid line) and the
system identified similar regions where the underlying accompaniment
repeats (dashed lines).
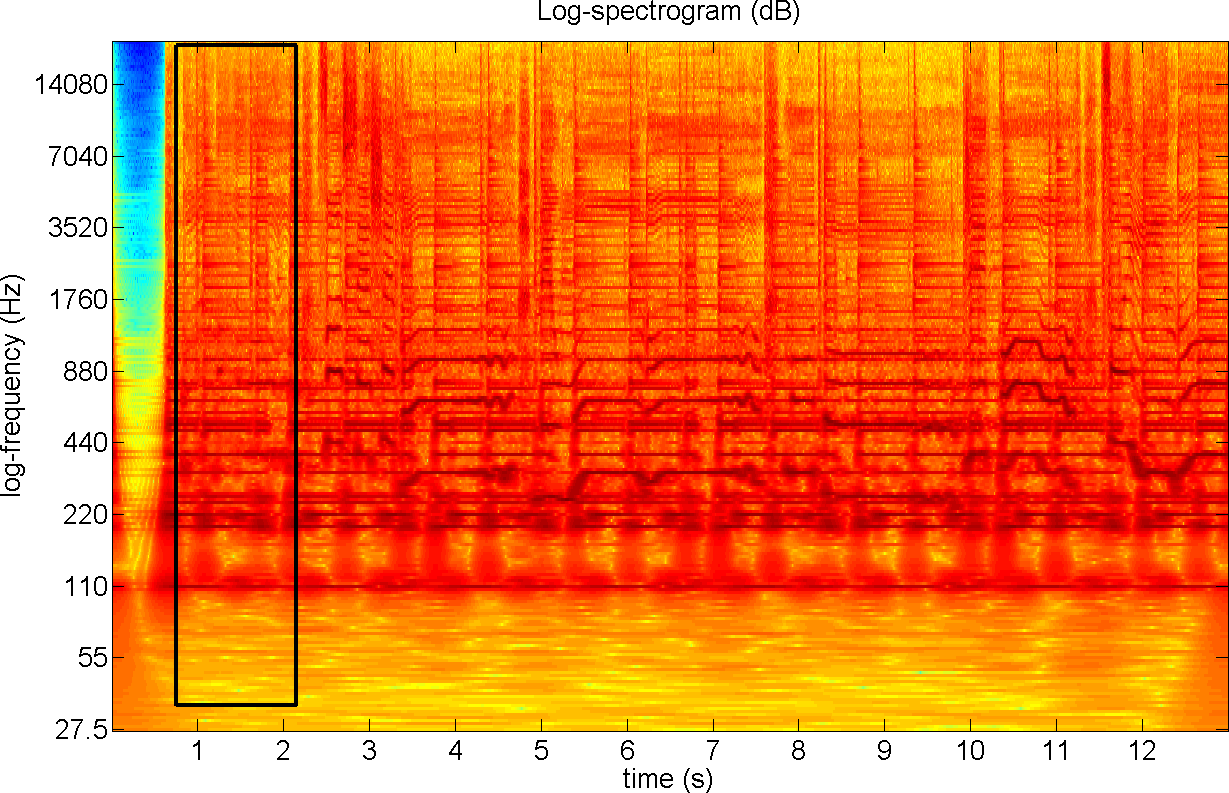
Fig. 11.
Log-spectrogram of the song with the first measure of the accompaniment
recovered. The system averaged the identified regions over their
repetitions and filtered out the vocals from the selected region.
[wav] accompaniment covered by vocals
[wav] recovered accompaniment: SDR=9.0 dB, SIR= 10.7 dB, SAR=14.3 dB (for the recovered measure)
[wav] original accompaniment
[wav] original vocals
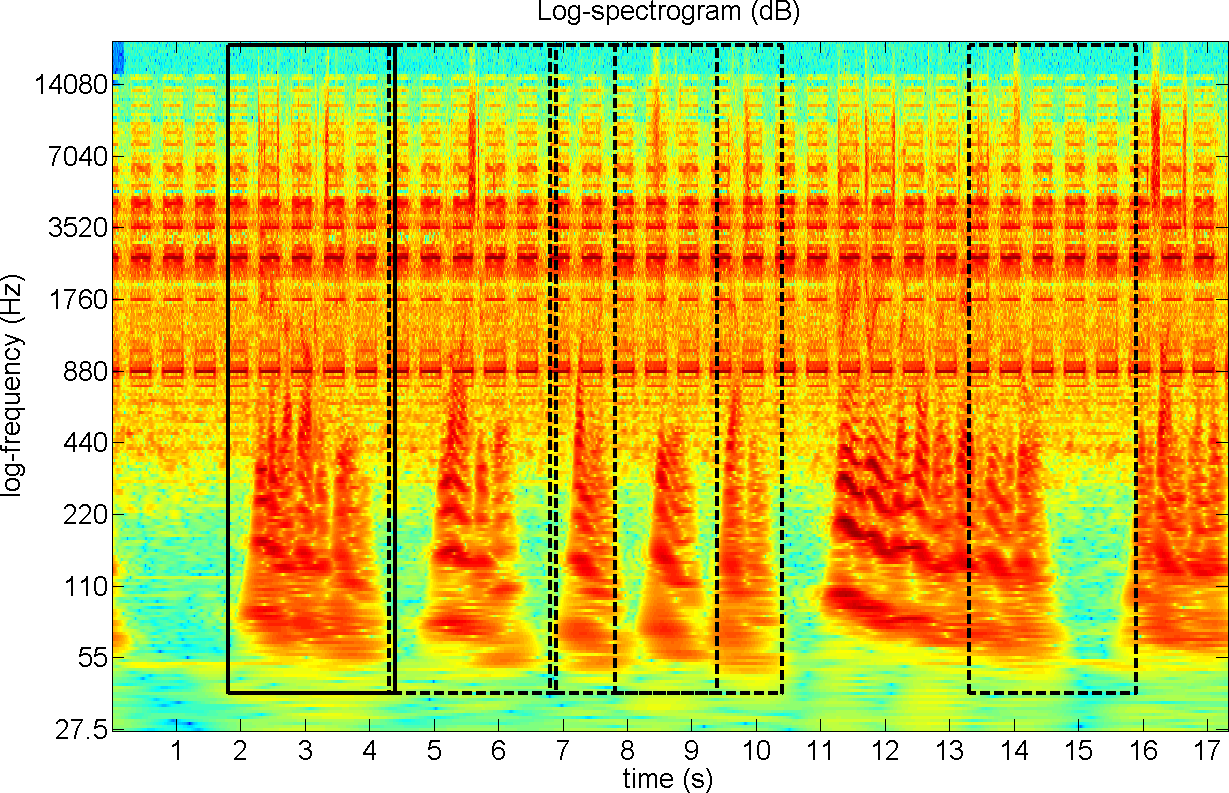
Fig. 12.
Log-spectrogram of a speech covering a noise. The user selected the
region of the first sentence (solid line) and the system identified
similar regions where the underlying noise repeats (dashed lines).
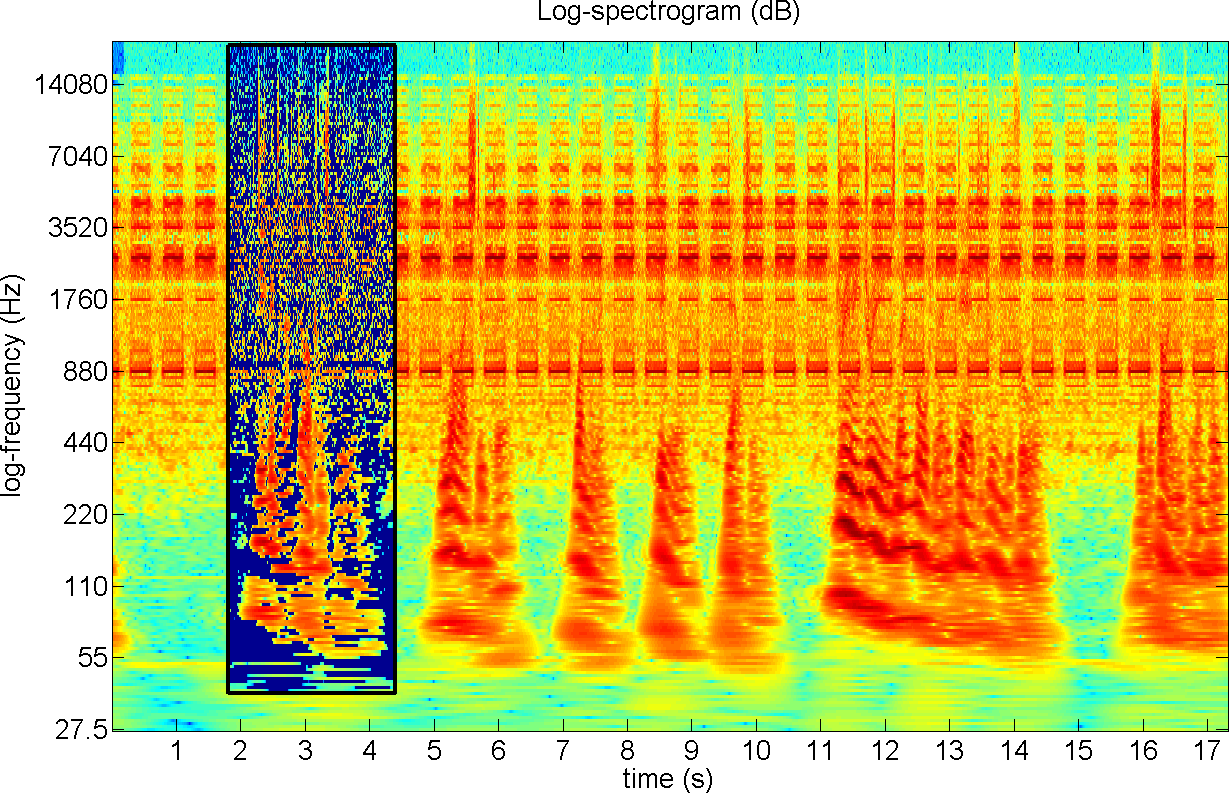
Fig. 13.
Log-spectrogram of the first sentence of the speech extracted. The
system averaged the identified regions over their repetitions and
extracted the speech from the selected region.
[wav] speech covering a noise
[wav] extracted speech: SDR=6.0 dB, SIR= 15.6 dB, SAR=7.8 dB (for the recovered sentence)
[wav] original speech
[wav] original noise
[gui] demo (tba)
[mat] Original REPET (update: September 2013)
[mat] REPET with segmentation (update: September 2013)
[mat] Adaptive REPET (update: September 2013)
[mat] REPET-SIM (update: September 2013)
[mat] Online REPET-SIM (update: September 2013)
[gui] Original REPET (demo) (update: September 2013)
[gui] REPET-SIM (update: September 2013)
[pdf] Bryan Pardo, Zafar Rafii, and Zhiyao Duan. "Audio Source Separation in Musical Context," Handbook of Systematic Musicology. (under review)
[pdf] Zafar Rafii, Zhiyao Duan, and Bryan Pardo. "Combining Rhythm-based and Pitch-based Methods for Background and Melody Separation," IEEE Transactions on Audio, Speech, and Language Processing, 22(12):1884-1893, December 2014.
[pdf] Zafar Rafii, Antoine Liutkus, and Bryan Pardo. "REPET for Background/Foreground Separation in Audio," Blind Source Separation, chapter 14, pages 395--411, Springer Berlin Heidelberg, 2014.
[pdf] Zafar Rafii, Francois G. Germain, Dennis L. Sun, and Gautham J. Mysore. “Combining Modeling of Singing Voice and Background Music for Automatic Separation of Musical Mixtures,” 14th International Society for Music Information Retrieval, Curutiba, PR, Brazil, November 4-8 2013. (poster)
[pdf] Zafar Rafii and Bryan Pardo. “Online REPET-SIM for Real-time Speech Enhancement,” 38th International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, May 26-31 2013. (poster)
[www] Zafar Rafii and Bryan Pardo. “Acoustic Separation System and Method,” US Patent No. 20,130,064,379. 14 March 2013.
[pdf] Zafar Rafii and Bryan Pardo. "REpeating Pattern Extraction Technique (REPET): A Simple Method for Music/Voice Separation," IEEE Transactions on Audio, Speech, and Language Processing, 21(1):71--82, January 2013.
[pdf] Josh McDermott, Bryan Pardo, and Zafar Rafii. “Leveraging Repetition to Parse the Auditory Scene,” 13th International Society for Music Information Retrieval, Porto, Portugal, October 8-12 2012.
[pdf] Zafar Rafii and Bryan Pardo. “Music/Voice Separation using the Similarity Matrix,” 13th International Society on Music Information Retrieval, Porto, Portugal, October 8-12 2012. (slides)
[pdf] Antoine Liutkus, Zafar Rafii, Roland Badeau, Bryan Pardo, and Gaël Richard. “Adaptive Filtering for Music/Voice Separation Exploiting the Repeating Musical Structure,” 37th International Conference on Acoustics, Speech and Signal Processing, Kyoto, Japan, March 25-30 2012. (slides)
[pdf] Zafar Rafii and Bryan Pardo. "A Simple Music/Voice Separation Method based on the Extraction of the Repeating Musical Structure," 36th International Conference on Acoustics, Speech and Signal Processing, Prague, Czech Republic, May 22-27 2011. (poster)
*This work was supported in part by National Science Foundation grant numbers IIS-0643752 and IIS-0812314, and by the Advanced Cognitive Science Fellowship for Interdisciplinary Research Projects of Northwestern University.